Wide & Deep Learning for Recommender Systems
模型简介
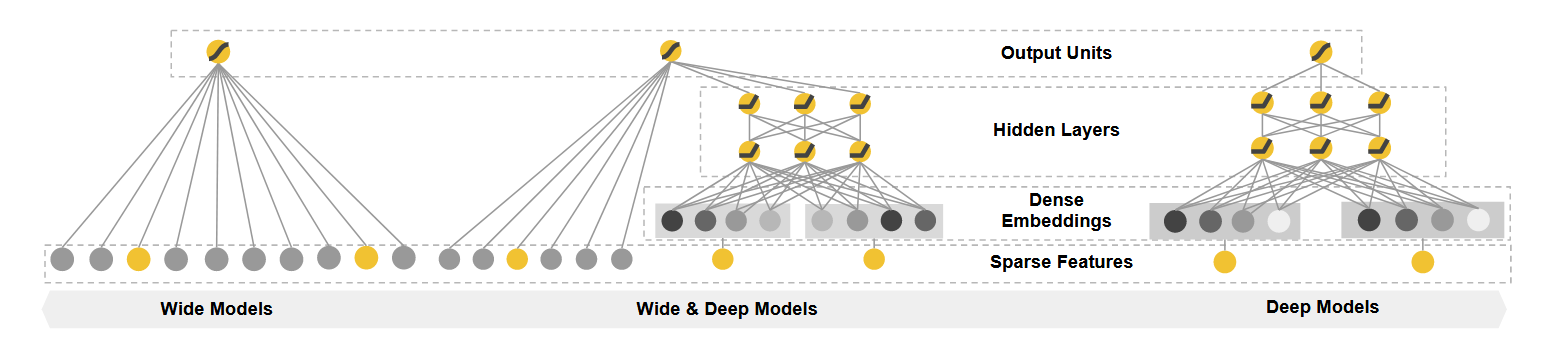
Wide & Deep 模型是 Google 在 2016 年提出的一个推荐系统模型,它巧妙地结合了线性模型的记忆能力(Memorization)和深度神经网络的泛化能力(Generalization),在 Google Play 商店的应用推荐中取得了显著效果。
Wide 侧:精准的特征记忆能力
模型结构
Wide 部分是一个广义线性模型: $y = w^T x + b$ 其中 $y$ 是预测值,$x = [x_1, x_2, …, x_d]$ 是特征向量,$w = [w_1, w_2, …, w_d]$ 是模型参数,$b$ 是偏置项。
特征交叉
- 交叉特征变换:$$\varphi_k(x) = \prod_{i=1}^{d} x_i^{c_{ki}},c_{ki}\in {0,1}$$
- 作用:捕捉特征间的相互作用,为模型引入非线性
- 示例:
AND(gender=female, language=en)特征,仅当两个条件同时满足时为1
Wide 侧的优势
- 强大的记忆能力:能够准确记住历史数据中的重要特征组合
- 模型简洁:参数量少,主要通过特征交叉来获取复杂模式
- 可解释性强:特征权重直观反映特征重要性
- 优化高效:采用 FTRL 算法配合 L1 正则化,适合处理稀疏特征
Deep 侧:强大的特征泛化能力
网络结构
-
Embedding 层
- 将高维稀疏特征转换为低维稠密向量
- 维度一般在 10-100 之间
- 通过端到端训练学习得到
-
隐藏层 每层的计算:$$a^{(l+1)} = f(W^{(l)}a^{(l)} + b^{(l)})$$
- 使用 ReLU 激活函数
- 多层非线性变换提供强大的特征抽取能力
- AdaGrad 优化器自适应调整学习率
Deep 侧的优势
- 强大的泛化能力:可以发现未出现过的特征组合
- 自动特征抽取:减少人工特征工程
- 处理高维特征:通过 Embedding 有效降维
模型融合与训练
联合预测
$$P(Y = 1 | x) = \sigma(w_{\text{wide}}^T [x, \varphi(x)] + w_{\text{deep}}^T a^{(l_f)} + b)$$
训练策略
- 联合训练:同时优化 Wide 和 Deep 两部分
- 互补性:Wide 侧记忆特定模式,Deep 侧负责泛化
- 增量训练:支持在线学习,可以持续优化模型
应用场景
- 推荐系统(用户-物品匹配)
- 广告点击率预测
- 搜索排序
- 任何需要同时处理记忆与泛化的场景
优缺点对比
| 维度 | Wide 部分 | Deep 部分 |
|---|---|---|
| 优势 | 记忆性强、可解释性好 | 泛化性强、自动特征组合 |
| 局限性 | 依赖特征工程、难以处理新组合 | 需要大量数据、计算成本较高 |
| 特征处理 | 离散特征交叉 | 连续/离散特征Embedding |
| 优化算法 | FTRL + L1 正则 | AdaGrad |
论文细节
Google Play 实践经验
- Wide 侧:重点使用用户已安装应用与候选应用的交叉特征
- Deep 侧:使用全量特征,三层 ReLU 网络(1200→256)
- 增量训练:复用历史模型参数快速更新
实验效果
-
实验设置
- 对照组:1% 用户使用优化的 Wide-only 模型
- 实验组:1% 用户使用 Wide & Deep 模型
- 特征配置:两组使用相同特征集
-
在线效果
- Wide & Deep vs Wide-only: +3.9% 应用获取率提升
- Wide & Deep vs Deep-only: +1.0% 应用获取率提升
- 所有提升均具有统计显著性
-
离线评估
- 指标:ROC 曲线下面积 (AUC)
- Wide & Deep 模型略优于基线模型
- 线上效果优于离线效果,作者推测原因:离线数据集展示和标签固定,在线系统可以探索性推荐,具有实时学习用户反馈

常见面试问题
Q1: 为什么要将 Wide 和 Deep 模型结合?
- 记忆与泛化互补:Wide 部分通过特征交叉记忆高频模式,Deep 部分通过 Embedding 泛化低频组合
- 工程实践平衡:Wide 保证关键规则不丢失,Deep 挖掘潜在关联
- 在线学习支持:Wide 部分可以快速更新响应数据变化
Q2: Wide 部分为什么使用 FTRL 优化器?
- 适应稀疏特征:FTRL 的稀疏解特性配合 L1 正则化能自动特征选择
- 在线学习友好:支持增量更新,适合处理流式数据
- 内存效率高:对不活跃特征自动置零,节省存储
Q3: 如何处理特征交叉?两种方式对比
| Wide 侧显式交叉 | Deep 侧隐式交叉 | |
|---|---|---|
| 实现方式 | 人工设计交叉特征 | Embedding 自动组合 |
| 计算复杂度 | 随特征维度指数增长 | 线性增长 |
| 可发现性 | 只能捕获已知组合 | 能发现未知组合 |
| 可解释性 | 权重明确反映特征重要性 | 黑箱难以解释 |
Q4: 模型训练有哪些注意事项?
- 特征去重:避免 Wide 和 Deep 侧输入完全相同特征
- 正则化配置:Wide 侧用 L1 正则,Deep 侧用 L2 正则
- 学习率调整:Wide 部分学习率通常比 Deep 部分小 10 倍
- 数据分布:确保在线/离线数据分布一致
Q5: 与 DeepFM 的区别?
- 特征交叉方式:DeepFM 用 FM 替代 Wide 部分,自动进行二阶特征交叉
- 参数共享:DeepFM 的 FM 和 Deep 共享 Embedding
- 工程复杂度:Wide&Deep 需要人工特征工程,DeepFM 自动化程度更高