DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
核心创新
DeepFM通过以下创新解决传统模型的局限性:
- Wide侧升级:用FM替代Wide & Deep中的LR
- 自动学习二阶特征交叉(原始Wide侧需人工特征工程)
- 保留FM的强记忆能力:$$y_{FM} = \langle w, x \rangle + \sum_{i=1}^{d}\sum_{j=i+1}^{d}\langle V_i, V_j \rangle x_i x_j$$
- 参数共享机制:FM与DNN共享Embedding
- 正则化作用:Embedding需同时满足低阶和高阶特征交互需求
- 参数效率:相比并行训练FM+DNN减少50%参数
- 端到端训练:无需FNN式的FM预训练阶段
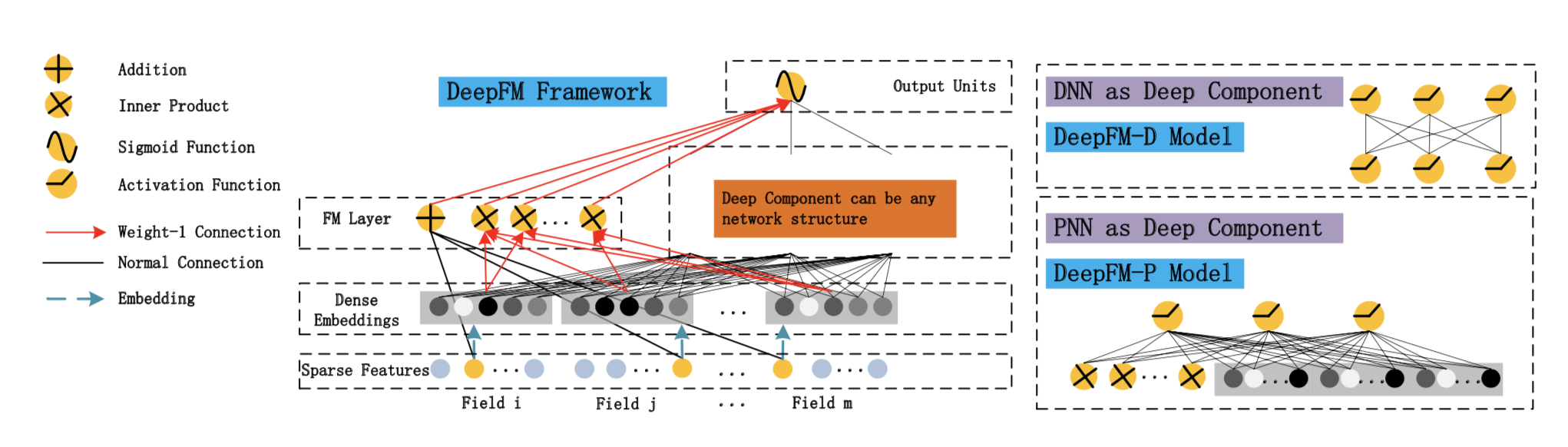
模型架构
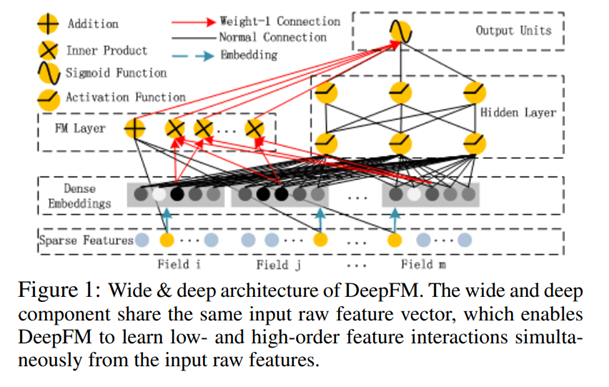
双通道结构
-
FM通道(低阶特征交互)
- 一阶项:线性特征权重(特征存在性判断)
- 表达特征间"或"的关系:每个特征的独立贡献
- 数学形式:$$\langle w, x \rangle = \sum_{i=1}^d w_i x_i$$
- 二阶项:隐向量内积(特征共现强度建模)
- 表达特征间"且"的关系:需要两个特征同时出现
- 计算优化:$$ \sum_{i=1}^{d}\sum_{j=i+1}^{d}\langle V_i, V_j \rangle x_i x_j = \frac{1}{2}[\left(\sum_{i=1}^d V_i x_i\right)^2 - \sum_{i=1}^d (V_i x_i)^2] $$
- 一阶项:线性特征权重(特征存在性判断)
-
DNN通道(高阶特征交互)
- 全连接网络自动学习高阶特征组合
- 输入层:与FM共享的Embedding拼接结果
- 隐藏层:3层ReLU网络(论文实验最优配置)
联合训练
$$ \hat{y} = \sigma(y_{FM} + y_{DNN}) $$
- 损失函数:交叉熵损失 $$ \mathcal{L} = -\frac{1}{N}\sum_{i=1}^N [y_i\log\hat{y}_i + (1-y_i)\log(1-\hat{y}_i)] $$
- 优化策略:两通道联合梯度下降(非交替训练)
- 论文实现细节:对稀疏特征使用Field-aware Embedding
工程实现细节
-
Embedding层优化:
- Field-aware处理:对不同特征域(field)使用独立Embedding矩阵
- 稀疏特征压缩:对高频特征进行哈希分桶
-
训练策略:
- 优化器:FM和DNN部分统一使用Adam算法
- 梯度裁剪:设置阈值5.0防止梯度爆炸
- Dropout:在DNN的最后一层前应用(rate=0.5)
技术优势
| 维度 | Wide & Deep | FNN | DeepFM |
|---|---|---|---|
| 特征工程需求 | 需要人工二阶特征 | 无 | 无 |
| 参数共享 | 无 | 顺序依赖 | 完全共享 |
| 训练方式 | 联合训练 | 分阶段 | 端到端 |
| 特征交互能力 | 二阶+高阶 | 高阶 | 全阶 |
| 参数初始化依赖 | 无 | FM预训练 | 无 |
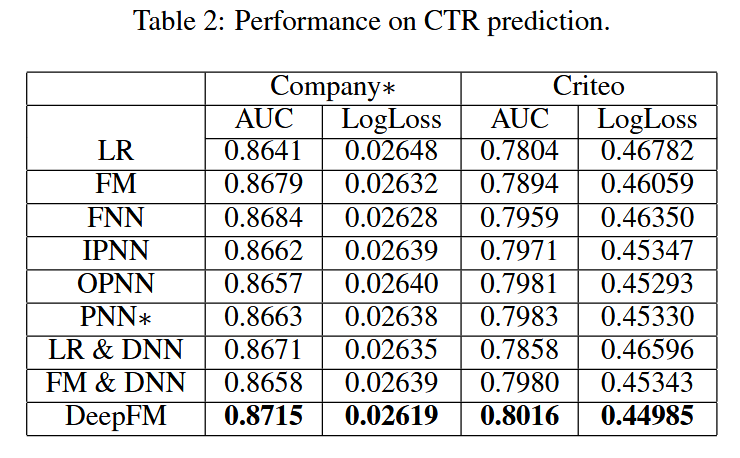
实验结论