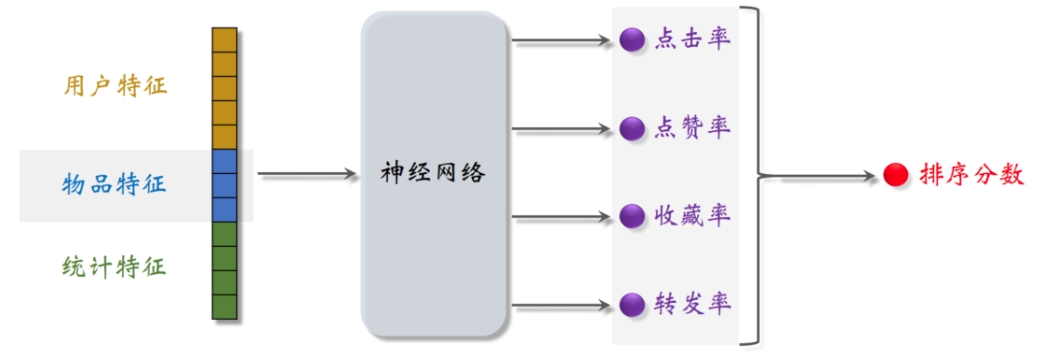
开始学习搜推,记录一下自己的笔记,第一件事情自然就是整个框架。这里参考了一下DataWhale以及王树森老师的资料
功能架构:Retrival-Rank架构
功能上就是经典的召回-排序架构,前面多后面少,召回用来找到备选项,精排排序打分,粗排弥补两者数据口径的矛盾,重排提升多样性以及塞广告
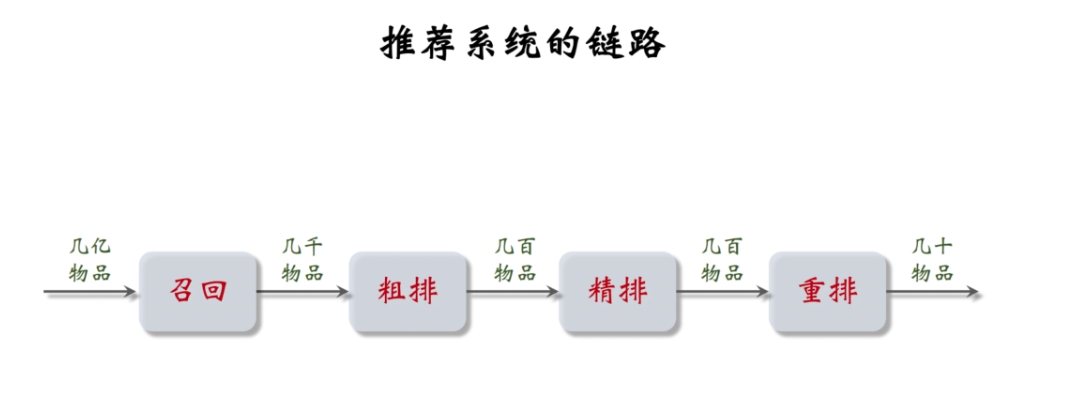

然后看了一下赵传霖的书,这里面写的还是挺详细的,感觉基本上把常见的一些都写进去了

数据架构:Lambda架构
数据上是大数据的Lambda架构,搜了一下这个架构好像是Twitter的一个工程师提出来的
Lambda architecture is a way of processing massive quantities of data (i.e.“Big Data”) that provides access to batch-processing and stream-processing methods with a hybrid approach. Lambda architecture is used to solve the problem of computing arbitrary functions. The lambda architecture itself is composed of 3 layers:
Batch Layer: New data comes continuously, as a feed to the data system. It gets fed to the batch layer and the speed layer simultaneously. It looks at all the data at once and eventually corrects the data in the stream layer. Here we can find lots of ETL and a traditional data warehouse. This layer is built using a predefined schedule, usually once or twice a day. The batch layer has two very important functions: To manage the master dataset and To pre-compute the batch views.
Serving Layer: The outputs from the batch layer in the form of batch views and those coming from the speed layer in the form of near real-time views get forwarded to the serving. This layer indexes the batch views so that they can be queried in low-latency on an ad-hoc basis.
Speed Layer (Stream Layer): This layer handles the data that are not already delivered in the batch view due to the latency of the batch layer. In addition, it only deals with recent data in order to provide a complete view of the data to the user by creating real-time views.
我贴一张网飞的图就清楚了,我总结为以下四点
- 把数据请求拆分成对冷、热数据的两个子请求
- 对于冷数据的子请求,交给离线层批量完成,结果缓存到近线层提供快速查询
- 对于热数据的子请求,交给在线层基于流式算法处理
- 汇总二者的子结果,得到最终的计算结果
