
端到端延迟计算
原题以及其翻译
Consider a packet of length L which begins at end system A and travels over three links to a destination end system. These three links are connected by two packet switches. Let di, si, and Ri denote the length, propagation speed, and the transmission rate of link i, for i = 1, 2, 3. The packet switch delays each packet by dproc. Assuming no queuing delays, in terms of di, si, Ri (i = 1,2,3), and L, what is the total end-to-end delay for the packet? Suppose now the packet is 1,500 bytes, the propagation speed on all three links is 2.5 X 108 m/s, the transmission rates of all three links are 2 Mbps, the packet switch processing delay is 3 msec, the length of the first link is 5,000 km, the length of the second link is 4,000 km, and the length of the last link is 1,000 km. For these values, what is the end-to-end delay?
考虑一个长度为 $L$ 的数据包,从端系统 A 开始,经过三条链路传输到目标端系统。这三条链路通过两个分组交换机连接。设链路 $i$ 的长度为 $d_i$,传播速度为 $s_i$,传输速率为 $R_i$,其中 $i = 1, 2, 3$。分组交换机对每个数据包的处理延迟为 $d_{proc}$。假设没有排队延迟,用 $d_i$、$s_i$、$R_i$($i = 1, 2, 3$)和 $L$ 表示数据包的总端到端延迟。
假设现在数据包长度为 1500 字节,所有三条链路的传播速度为 $2.5 \times 10^8$ 米/秒,所有三条链路的传输速率为 2 Mbps,分组交换机的处理延迟为 3 毫秒,第一条链路的长度为 5000 千米,第二条链路的长度为 4000 千米,最后一条链路的长度为 1000 千米。对于这些值,端到端延迟是多少?
四种时延总结
传输延迟(Transmission Delay)
- 英文:Transmission Delay
- 定义:将数据包从发送端传输到链路(或介质)上的时间。
- 计算公式:
$$
\text{传输延迟} = \frac{\text{数据包长度(比特数)}}{\text{链路传输速率(比特/秒)}}
$$
即:
$$
\text{传输延迟} = \frac{L}{R}
$$
其中:
- $L$ 是数据包长度(单位:比特)。
- $R$ 是链路的传输速率(单位:比特/秒,如 Mbps)。
传播延迟(Propagation Delay)
- 英文:Propagation Delay
- 定义:数据包在链路上从一端传播到另一端的时间。
- 计算公式:
$$
\text{传播延迟} = \frac{\text{链路长度(米)}}{\text{传播速度(米/秒)}}
$$
即:
$$
\text{传播延迟} = \frac{d}{s}
$$
其中:
- $d$ 是链路长度(单位:米)。
- $s$ 是传播速度(单位:米/秒,通常接近光速,如 $2 \times 10^8$ 米/秒)。
处理延迟(Processing Delay)
- 英文:Processing Delay
- 定义:交换机或路由器处理数据包的时间,包括检查头部信息、决定路由等操作。
- 计算公式:
- 处理延迟通常是一个常数,表示为 $d_{proc}$。
- 例如,处理延迟可能为 1 毫秒(ms)或 0.001 秒。
排队延迟(Queuing Delay)
- 英文:Queuing Delay
- 定义:数据包在交换机或路由器的队列中等待传输的时间。
- 计算公式:
- 排队延迟取决于网络流量和队列长度,通常难以精确计算。
- 在理想情况下(如无排队),排队延迟为 0。
- 在实际网络中,排队延迟可能因网络拥塞而显著增加。
总端到端延迟(End-to-End Delay)
在实际网络中,数据包的总端到端延迟是上述四种延迟的总和。对于一个简单的网络路径,总端到端延迟可以表示为: $$ \text{总端到端延迟} = \sum (\text{传输延迟} + \text{传播延迟}) + \sum \text{处理延迟} + \text{排队延迟} $$
在没有排队延迟的情况下(如题目假设),总端到端延迟简化为: $$ \text{总端到端延迟} = \sum_{i=1}^{n} \left( \frac{L}{R_i} + \frac{d_i}{s_i} \right) + \sum_{j=1}^{m} d_{proc,j} $$ 其中:
- $n$ 是链路的数量。
- $m$ 是交换机的数量。
解题步骤
推导通用公式
我们需要计算总端到端延迟,包括以下几部分:
- 传输延迟:每个链路将数据包从一个端点传输到另一个端点所需的时间。对于链路 $i$,传输延迟为: $$ \text{传输延迟}_i = \frac{L}{R_i} $$
- 传播延迟:数据包在链路上的传播时间。对于链路 $i$,传播延迟为: $$ \text{传播延迟}_i = \frac{d_i}{s_i} $$
- 交换机处理延迟:每个交换机处理数据包的时间。假设每个交换机的处理延迟为 $d_{proc}$,因为有两个交换机,所以总处理延迟为: $$ 2 \times d_{proc} $$
因此,总端到端延迟为: $$ \text{总端到端延迟} = \sum_{i=1}^{3} \left( \frac{L}{R_i} + \frac{d_i}{s_i} \right) + 2 \times d_{proc} $$
2. 带入具体参数进行计算
根据题目给定的参数:
- 数据包长度 $L = 1500$ 字节 = $1500 \times 8$ 比特 = 12000 比特
- 传播速度 $s_1 = s_2 = s_3 = 2.5 \times 10^8$ 米/秒
- 传输速率 $R_1 = R_2 = R_3 = 2$ Mbps = $2 \times 10^6$ 比特/秒
- 处理延迟 $d_{proc} = 3$ 毫秒 = 0.003 秒
- 链路长度 $d_1 = 5000$ 千米 = $5 \times 10^6$ 米,$d_2 = 4000$ 千米 = $4 \times 10^6$ 米,$d_3 = 1000$ 千米 = $1 \times 10^6$ 米
分别计算每个链路的延迟:
链路 1: $$ \text{传输延迟}_1 = \frac{12000}{2 \times 10^6} = 0.006 \text{ 秒} $$ $$ \text{传播延迟}_1 = \frac{5 \times 10^6}{2.5 \times 10^8} = 0.02 \text{ 秒} $$
链路 2: $$ \text{传输延迟}_2 = \frac{12000}{2 \times 10^6} = 0.006 \text{ 秒} $$ $$ \text{传播延迟}_2 = \frac{4 \times 10^6}{2.5 \times 10^8} = 0.016 \text{ 秒} $$
链路 3: $$ \text{传输延迟}_3 = \frac{12000}{2 \times 10^6} = 0.006 \text{ 秒} $$ $$ \text{传播延迟}_3 = \frac{1 \times 10^6}{2.5 \times 10^8} = 0.004 \text{ 秒} $$
总端到端延迟: $$ \text{总端到端延迟} = (0.006 + 0.02) + (0.006 + 0.016) + (0.006 + 0.004) + 2 \times 0.003 = 0.063 \text{ 秒} $$
因此,端到端延迟为 0.063 秒。
分组交换时间计算
原题和翻译
In modern packet-switched networks, including the Internet, the source host segments long, applicationlayer messages (for example, an image or a music file) into smaller packets and sends the packets into the network. The receiver then reassembles the packets back into the original message. This is called message segmentation. Consider the figure below:
在现代分组交换网络中(包括互联网),源主机将长的应用层消息(例如,图像或音乐文件)分割成较小的数据包,并将这些数据包发送到网络中。接收端再将数据包重新组装成原始消息。这一过程称为消息分段(message segmentation)。请考虑以下情况:
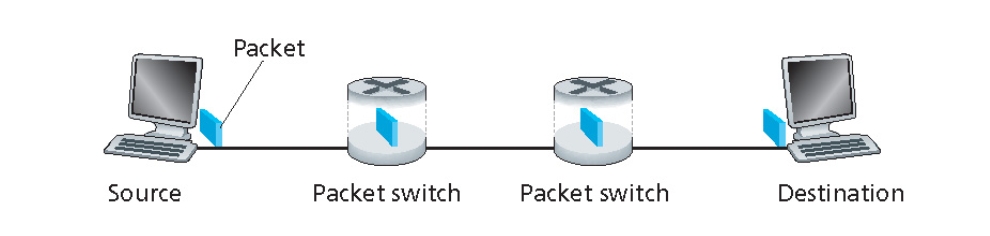
Consider a message that is 8 X 106 bits long that is to be sent from source to destination. Suppose each link in the figure is 2 Mbps. Ignore propagation, queuing, and processing delays.
假设一个消息长度为 8×106 比特,需要从源端发送到目标端。假设图中的每条链路速率为 2 Mbps。忽略传播延迟、排队延迟和处理延迟。
a. Consider sending the message from source to destination without message segmentation. How long does it take to move the message from the source host to the first packet switch? Keeping in mind that each switch uses store-and-forward packet switching, what is the total time to move the message from source host to destination host?
a. 考虑不使用消息分段的情况下,将消息从源主机发送到第一个分组交换机需要多长时间?考虑到每个交换机都使用存储-转发分组交换方式,从源主机到目标主机的总时间是多少?
b. Now suppose that the message is segmented into 800 packets, with each packet being 10,000 bits long. How long does it take to move the first packet from source host to the first switch? When the first packet is being sent from the first switch to the second switch, the second packet is being sent from the source host to the first switch. At what time will the second packet be fully received at the first switch?
b. 现在假设消息被分割成 800 个数据包,每个数据包长度为 10,000 比特。将第一个数据包从源主机发送到第一个交换机需要多长时间?当第一个数据包从第一个交换机发送到第二个交换机时,第二个数据包正在从源主机发送到第一个交换机。第二个数据包在第一个交换机处被完全接收的时间是多少?
c. How long does it take to move the file from source host to destination host when message segmentation is used?
c. 使用消息分段时,将文件从源主机发送到目标主机需要多长时间?
d. What are the reasons to use message segmentation?
d. 使用消息分段的原因是什么?
e. What are the drawbacks of message segmentation?
e. 消息分段的缺点是什么?
解题步骤
不使用消息分段
-
从源主机到第一个交换机的时间:
- 消息长度为$8 \times 10^6$ 比特。
- 链路速率为 2 Mbps =$2 \times 10^6$ 比特/秒。
- 传输时间 = 消息长度 / 链路速率: $$ \text{传输时间} = \frac{8 \times 10^6 \text{ 比特}}{2 \times 10^6 \text{ 比特/秒}} = 4 \text{ 秒} $$
-
从源主机到目标主机的总时间:
- 因为没有分段,整个消息需要在每个交换机处完全接收后再发送。
- 假设链路速率不变,总时间仍然是 4 秒(因为消息是连续传输的)。
使用消息分段
-
第一个数据包从源主机到第一个交换机的时间:
- 数据包长度为 10,000 比特。
- 链路速率为 2 Mbps =$2 \times 10^6$ 比特/秒。
- 传输时间 = 数据包长度 / 链路速率: $$ \text{传输时间} = \frac{10,000 \text{ 比特}}{2 \times 10^6 \text{ 比特/秒}} = 0.005 \text{ 秒} $$
-
第二个数据包在第一个交换机处被完全接收的时间:
- 第一个数据包到达第一个交换机的时间为 0.005 秒。
- 第二个数据包开始传输的时间为 0.005 秒(因为第一个数据包传输完成后,第二个数据包立即开始传输)。
- 第二个数据包到达第一个交换机的时间为$0.005 + 0.005 = 0.01 \text{ 秒}$。
使用消息分段时,整个文件从源主机到目标主机的总时间
- 每个数据包的传输时间:
- 每个数据包长度为 10,000 比特。
- 链路速率为 2 Mbps =$2 \times 10^6$ 比特/秒。
- 传输时间 = 数据包长度 / 链路速率: $$ \text{传输时间} = \frac{10,000 \text{ 比特}}{2 \times 10^6 \text{ 比特/秒}} = 0.005 \text{ 秒} $$
- 总时间:
- 有 800 个数据包。
- 每个数据包的传输时间为 0.005 秒。
- 总时间为$800 \times 0.005 = 4 \text{ 秒}$。
Reasons to Use Message Segmentation / 使用消息分段的原因
-
Improve Network Utilization / 提高网络利用率:
- Smaller packets can traverse the network more quickly, reducing wait times. / 小数据包可以更快地通过网络,减少等待时间。
- If some packets are lost or corrupted, only the problematic packets need to be retransmitted, not the entire message. / 即使某些数据包丢失或出错,也只需要重传有问题的数据包,而不是整个消息。
-
Enhance Reliability / 提高可靠性:
- Smaller packets are easier to manage and have a lower probability of errors. / 小数据包更容易管理,出错的概率较低。
- The receiver can more quickly detect errors and request retransmissions. / 接收端可以更快地检测到错误并请求重传。
-
Adapt to Network Limitations / 适应网络限制:
- Network devices (such as switches and routers) may have limitations on packet size. / 网络设备(如交换机、路由器)可能对数据包大小有限制。
- Segmentation ensures that packets meet the requirements of network devices. / 分段可以确保数据包符合网络设备的要求。
Drawbacks of Message Segmentation / 消息分段的缺点
-
Increased Overhead / 增加开销:
- Each packet requires additional header information (such as an IP header), which consumes some bandwidth. / 每个数据包需要额外的头部信息(如 IP 头部),这会占用一些带宽。
- The receiver needs to reassemble the packets, which increases the processing burden. / 接收端需要重新组装数据包,增加了处理负担。
-
Increased Complexity / 增加复杂性:
- Packet segmentation and reassembly require additional protocol support. / 数据包的分段和重组需要额外的协议支持。
- If packets are lost or arrive out of order, the receiver needs to handle these issues. / 如果数据包丢失或乱序到达,接收端需要处理这些问题。
DNS 查询 & Web对象获取
题目和翻译
Suppose within your Web browser you click on a link to obtain a Web page. The IP address for the associated URL is not cached in your local host, so a DNS lookup is necessary to obtain the IP address. Suppose that n DNS servers are visited before your host receives the IP address from DNS: visiting k of them incurs a RTT of D1, per DNS and visiting each of the remaining incurs a RTT of D2. Further suppose that the Web page associated with the link contains m very small objects. Suppose HTTP is non-persistent and let RTT0 denote the RTT between the local host and the server containing the object. Assuming zero transmission time for each object, how much time elapses from when the client clicks on the link until the client receives all objects?
假设在您的 Web 浏览器中,您点击了一个链接以获取一个网页。与该 URL 相关联的 IP 地址没有缓存在您的本地主机中,因此需要进行 DNS 查询以获取 IP 地址。假设在您的主机从 DNS 收到 IP 地址之前,访问了$n$ 个 DNS 服务器:访问其中$k$ 个 DNS 服务器的往返时间(RTT)为$D1$,访问其余$(n - k)$ 个 DNS 服务器的往返时间(RTT)为$D2$。此外,假设与该链接相关的网页包含$m$ 个非常小的对象。假设 HTTP 是非持续的(non-persistent),并且用$RTT0$ 表示本地主机和包含对象的服务器之间的往返时间。假设每个对象的传输时间为零,从客户端点击链接到客户端接收所有对象需要多长时间?
解题步骤
-
DNS 查询时间:
- 访问$k$ 个 DNS 服务器的总时间:( k \times D1$
- 访问剩余$(n - k)$ 个 DNS 服务器的总时间:( (n - k) \times D2$
- 因此,获取 IP 地址的总时间为: $$ \text{DNS 查询总时间} = k \times D1 + (n - k) \times D2 $$
-
获取网页对象的时间:
- 由于 HTTP 是非持续的,每个对象都需要单独建立一个 TCP 连接。
- 每个对象的获取时间包括一个往返时间$RTT0$。
- 因此,获取所有$m$ 个对象的总时间为: $$ \text{获取所有对象的时间} = m \times RTT0 $$
-
总时间:
- 从客户端点击链接到接收所有对象的总时间为 DNS 查询时间和获取所有对象时间的总和: $$ \text{总时间} = (k \times D1 + (n - k) \times D2) + m \times RTT0 $$
题目和翻译
Referring to Problem 1, suppose three DNS servers are visited and the value of k is 2. Furthermore, the HTML file references 5 small objects on the same server. Neglecting transmission times, how much time elapses with:
a. Non-persistent HTTP with no parallel connections?
b. Non-persistent HTTP with the server configured for five parallel connections?
c. Persistent HTTP with the server configured for five parallel connections?
Problem 3
参考 Problem 1,假设访问了 3 个 DNS 服务器,其中$k$ 的值为 2。此外,HTML 文件引用了同一服务器上的 5 个小型对象。忽略传输时间,分别计算以下情况的时间: a. 非持续 HTTP,且没有并行连接? b. 非持续 HTTP,服务器配置为支持五个并行连接? c. 持续 HTTP,服务器配置为支持五个并行连接?
核心要点
- 非持续HTTP:
- 串行连接:每个对象需要一个完整的RTT,总时间是所有对象的RTT之和。
- 并行连接:多个对象可以同时传输,总时间只需要一个RTT。
- 持续HTTP:
- 串行连接:所有对象通过同一个连接传输,总时间只需要一个RTT。
- 并行连接:多个对象可以通过并行连接同时传输,总时间仍然是一个RTT。
解题步骤
根据 Problem 1 的背景,我们已知:
- 访问了 3 个 DNS 服务器,其中$k = 2$。
- HTML 文件引用了 5 个小型对象。
- 忽略每个对象的传输时间。
假设: -$D1 = 10$ ms(假设值) -$D2 = 20$ ms(假设值) -$RTT0 = 50$ ms(假设值)
a. 非持续 HTTP,且没有并行连接
-
DNS 查询时间:
- 访问 2 个 DNS 服务器的总时间:( 2 \times D1 = 2 \times 10 = 20$ ms
- 访问 1 个 DNS 服务器的总时间:( 1 \times D2 = 1 \times 20 = 20$ ms
- 因此,获取 IP 地址的总时间为: $$ \text{DNS 查询总时间} = 20 + 20 = 40 \text{ ms} $$
-
获取网页对象的时间:
- 每个对象需要单独建立一个 TCP 连接,因此总时间为: $$ \text{获取所有对象的时间} = 5 \times RTT0 = 5 \times 50 = 250 \text{ ms} $$
-
总时间: $$ \text{总时间} = 40 + 250 = 290 \text{ ms} $$
b. 非持续 HTTP,服务器配置为支持五个并行连接
-
DNS 查询时间:
- 与前面相同: $$ \text{DNS 查询总时间} = 40 \text{ ms} $$
-
获取网页对象的时间:
- 由于支持并行连接,所有 5 个对象可以同时传输,因此总时间为一个往返时间: $$ \text{获取所有对象的时间} = RTT0 = 50 \text{ ms} $$
-
总时间: $$ \text{总时间} = 40 + 50 = 90 \text{ ms} $$
c. 持续 HTTP,服务器配置为支持五个并行连接
-
DNS 查询时间:
- 与前面相同: $$ \text{DNS 查询总时间} = 40 \text{ ms} $$
-
获取网页对象的时间:
- 在持续 HTTP 中,所有对象可以通过同一个 TCP 连接传输,因此总时间为一个往返时间: $$ \text{获取所有对象的时间} = RTT0 = 50 \text{ ms} $$
-
总时间: $$ \text{总时间} = 40 + 50 = 90 \text{ ms} $$
DNS 递归查询 & 迭代查询
Suppose that the local DNS server caches all information coming in from all root, TLD, and authoritative DNS servers for 20 time units. (Thus, for example, when a root server returns the name and address of a TLD server for .com, the cache remembers that this is the TLD server to use to resolve a .com name). Assume also that the local cache is initially empty, that iterative DNS queries are always used, that DNS requests are just for name-to-IP-address translation, that 1 time unit is needed for each server-to-server or host-to-server (one way) request/response, and that there is only one authoritative name server (each) for any .edu or .com domain.
Find the time units taken to resolve each of the following DNS requests made by the local host. a. t=0, the local host requests that the name gaia.cs.umass.edu be resolved to an IP address. b. t=1, the local host requests that the name icann.org be resolved to an IP address. c. t=5, the local host requests that the name cs.umd.edu be resolved to an IP address. d. t=10, the local host again requests that the name gaia.cs.umass.edu be resolved to an IP address. e. t=30, the local host again requests that the name icann.org be resolved to an IP address.
假设本地 DNS 服务器将来自所有根服务器、顶级域(TLD)服务器和权威 DNS 服务器的所有信息缓存 20 个时间单位。例如,当根服务器返回 .com 的 TLD 服务器的名称和地址时,缓存会记住这是用于解析 .com 域名的 TLD 服务器。同时假设本地缓存最初为空,总是使用迭代 DNS 查询,DNS 请求仅用于名称到 IP 地址的转换,每个服务器到服务器或主机到服务器(单向)请求/响应需要 1 个时间单位,并且对于任何 .edu 或 .com 域,只有一个权威名称服务器。
找出本地主机发起的以下每次DNS请求所花费的时间单位。
a. t=0,本地主机请求将名称gaia.cs.umass.edu解析为IP地址。 b. t=1,本地主机请求将名称icann.org解析为IP地址。 c. t=5,本地主机请求将名称cs.umd.edu解析为IP地址。 d. t=10,本地主机再次请求将名称gaia.cs.umass.edu解析为IP地址。 e. t=30,本地主机再次请求将名称icann.org解析为IP地址。
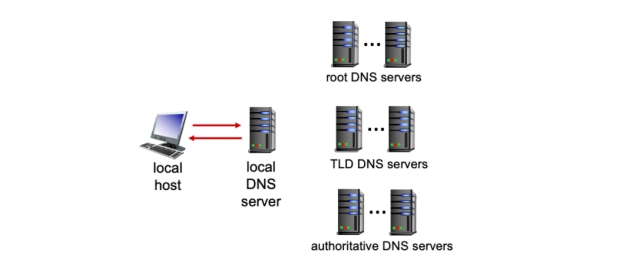
好的,我们来总结一下 迭代查询(Iterative Query) 和 递归查询(Recursive Query) 在DNS查询中的计算要点。这两种查询方式在DNS解析过程中有显著的区别,特别是在查询时间和资源消耗方面。
迭代查询(Iterative Query)
- 迭代查询:客户端向其本地DNS服务器发送查询请求,本地DNS服务器返回一个指向更接近目标的DNS服务器的引用(如根服务器、TLD服务器或权威DNS服务器)。客户端随后直接向这些服务器发送查询请求,直到获取最终的IP地址。
- 查询路径:
- 客户端依次向根服务器、TLD服务器和权威DNS服务器发送查询请求。
- 每个服务器返回一个指向下一个服务器的引用,直到最终获取目标域名的IP地址。
- 时间计算: - 每个请求/响应需要一个时间单位(假设单向请求/响应时间为1个时间单位)。 - 总时间 = 根服务器查询时间 + TLD服务器查询时间 + 权威DNS服务器查询时间。 - 例如,对于一个典型的查询路径(根服务器 -> TLD服务器 -> 权威DNS服务器),总时间为 (3 \times 2 = 6) 个时间单位(往返时间)。
- 资源消耗: - 客户端需要多次发送查询请求,因此客户端的网络负载较高。 - 本地DNS服务器的负载较低,因为它只提供引用,不直接参与最终的解析。
- 缓存的影响: - 如果本地DNS服务器或客户端缓存了某些中间结果(如TLD服务器的地址),可以减少查询时间。 - 缓存的有效期(如20个时间单位)会影响是否需要重新查询。
递归查询(Recursive Query)
- 递归查询:客户端向其本地DNS服务器发送查询请求,本地DNS服务器负责完成整个解析过程,并将最终的IP地址返回给客户端。客户端不需要直接与根服务器、TLD服务器或权威DNS服务器交互。
- 查询路径:
- 客户端向本地DNS服务器发送查询请求。
- 本地DNS服务器依次向根服务器、TLD服务器和权威DNS服务器发送查询请求,直到获取目标域名的IP地址。
- 本地DNS服务器将最终的IP地址返回给客户端。
- 时间计算:
- 每个请求/响应需要一个时间单位(假设单向请求/响应时间为1个时间单位)。
- 总时间 = 根服务器查询时间 + TLD服务器查询时间 + 权威DNS服务器查询时间。
- 例如,对于一个典型的查询路径(根服务器 -> TLD服务器 -> 权威DNS服务器),总时间为 (3 \times 2 = 6) 个时间单位(往返时间)。
- 与迭代查询不同,递归查询的总时间是从客户端的角度计算的,客户端只需要等待最终结果。
- 资源消耗:
- 客户端只需要发送一次查询请求,因此客户端的网络负载较低。
- 本地DNS服务器的负载较高,因为它需要完成整个解析过程。
- 缓存的影响:
- 如果本地DNS服务器缓存了某些中间结果(如TLD服务器的地址),可以减少查询时间。
- 缓存的有效期(如20个时间单位)会影响是否需要重新查询。
解题步骤
a. t=0, 本地主机请求将名称 gaia.cs.umass.edu 解析为 IP 地址。
- 查询过程:
- 本地 DNS 服务器向根服务器发送请求。
- 根服务器返回 .edu 的 TLD 服务器的地址。
- 本地 DNS 服务器向 .edu 的 TLD 服务器发送请求。
- TLD 服务器返回 gaia.cs.umass.edu 的权威 DNS 服务器的地址。
- 本地 DNS 服务器向 gaia.cs.umass.edu 的权威 DNS 服务器发送请求。
- 权威 DNS 服务器返回 gaia.cs.umass.edu 的 IP 地址。
- 时间计算:
- 每个请求/响应需要 1 个时间单位。
- 总共需要 5 个时间单位(根服务器、TLD 服务器、权威 DNS 服务器各 1 个时间单位,往返共 5 个时间单位)。
b. t=1, 本地主机请求将名称 icann.org 解析为 IP 地址。
- 查询过程:
- 本地 DNS 服务器向根服务器发送请求。
- 根服务器返回 .org 的 TLD 服务器的地址。
- 本地 DNS 服务器向 .org 的 TLD 服务器发送请求。
- TLD 服务器返回 icann.org 的权威 DNS 服务器的地址。
- 本地 DNS 服务器向 icann.org 的权威 DNS 服务器发送请求。
- 权威 DNS 服务器返回 icann.org 的 IP 地址。
- 时间计算:
- 每个请求/响应需要 1 个时间单位。
- 总共需要 5 个时间单位(根服务器、TLD 服务器、权威 DNS 服务器各 1 个时间单位,往返共 5 个时间单位)。
c. t=5, 本地主机请求将名称 cs.umd.edu 解析为 IP 地址。
- 查询过程:
- 本地 DNS 服务器向根服务器发送请求。
- 根服务器返回 .edu 的 TLD 服务器的地址。
- 本地 DNS 服务器向 .edu 的 TLD 服务器发送请求。
- TLD 服务器返回 cs.umd.edu 的权威 DNS 服务器的地址。
- 本地 DNS 服务器向 cs.umd.edu 的权威 DNS 服务器发送请求。
- 权威 DNS 服务器返回 cs.umd.edu 的 IP 地址。
- 时间计算:
- 每个请求/响应需要 1 个时间单位。
- 总共需要 5 个时间单位(根服务器、TLD 服务器、权威 DNS 服务器各 1 个时间单位,往返共 5 个时间单位)。
d. t=10, 本地主机再次请求将名称 gaia.cs.umass.edu 解析为 IP 地址。
- 查询过程:
- 由于 gaia.cs.umass.edu 的信息已经在缓存中(从 t=0 开始,缓存时间为 20 个时间单位),本地 DNS 服务器直接从缓存中返回 IP 地址。
- 时间计算:
- 从缓存中读取信息不需要额外的时间单位。
- 总共需要 0 个时间单位。
e. t=30, 本地主机再次请求将名称 icann.org 解析为 IP 地址。
- 查询过程:
- 由于 icann.org 的信息已经在缓存中(从 t=1 开始,缓存时间为 20 个时间单位),本地 DNS 服务器直接从缓存中返回 IP 地址。
- 时间计算:
- 从缓存中读取信息不需要额外的时间单位。
- 总共需要 0 个时间单位。
总结
- t=0, gaia.cs.umass.edu:5 个时间单位
- t=1, icann.org:5 个时间单位
- t=5, cs.umd.edu:5 个时间单位
- t=10, gaia.cs.umass.edu:0 个时间单位
- t=30, icann.org:0 个时间单位
GBN 协议理解
题目和翻译
Consider the GBN protocol with a sender window size of 4 and a sequence number range of 1,024. Suppose that at time t, the next in-order packet that the receiver is expecting has a sequence number of k. Assume that the medium does not reorder messages. Answer the following questions:
a. What are the possible sets of sequence numbers inside the sender’s window at time t?
b. What are all possible values of the ACK field in all possible messages currently propagating back to the sender at time t
考虑一个具有发送窗口大小为4和序号范围为1024的GBN(Go-Back-N)协议。 假设在时间t时,接收方期望接收的下一个按序号顺序的报文的序号为k。假设传输介质不会对报文进行重新排序。回答以下问题: a. 在时间t时,发送方窗口中可能的序号集合是什么? b. 在时间t时,所有可能正在向发送方传播的报文中的ACK字段的所有可能值是什么?
GBN 协议介绍
好的!GBN(Go-Back-N)协议是一种基于滑动窗口的可靠传输协议,广泛用于计算机网络中的数据传输。它的核心思想是通过序号、确认(ACK)机制和滑动窗口来确保数据的可靠传输。下面详细解释GBN协议的工作原理、关键特性以及它在实际场景中的应用。
序号和确认(ACK)机制
- 序号:每个发送的数据包都有一个唯一的序号,用于标识数据包的顺序。序号是循环使用的,例如在一个序号范围为1024的系统中,序号从0到1023循环。
- 确认(ACK):接收方在正确接收到一个数据包后,会发送一个确认(ACK)消息,告诉发送方它已经成功接收了哪些数据包。ACK消息中包含接收方期望接收的下一个数据包的序号。
滑动窗口
- 发送窗口:发送方维护一个滑动窗口,表示它可以发送但尚未收到确认的数据包的范围。窗口大小决定了发送方可以连续发送的数据包数量,而无需等待确认。
- 接收窗口:接收方也维护一个窗口,但接收窗口的大小通常为1(GBN协议的特性)。接收方只接收按序号顺序到达的数据包,如果接收到乱序的数据包,会直接丢弃。
数据传输过程
- 发送数据包:发送方从窗口的起始位置开始发送数据包,直到窗口的末尾。发送方记录每个数据包的序号,并启动一个计时器等待确认。
- 接收数据包:接收方按序号顺序接收数据包。如果接收到的数据包序号是它期望的下一个序号,接收方会接收该数据包并发送一个ACK消息,确认它已经接收了哪些数据包。
- 确认和窗口滑动:发送方收到ACK消息后,根据ACK消息中的序号更新窗口的位置。如果ACK消息表明接收方已经接收了窗口中的某些数据包,发送方会将窗口向前滑动,继续发送新的数据包。
- 超时重传:如果发送方在计时器超时后仍未收到某个数据包的确认,它会假设该数据包丢失,并重新发送从该数据包开始的所有后续数据包(即“Go-Back-N”)。
Go-Back-N机制
- 当检测到某个数据包丢失时,发送方不会只重传丢失的数据包,而是重新发送从丢失的数据包开始的所有后续数据包。这种机制的优点是简单,但缺点是可能导致不必要的重传,尤其是在网络环境较差时。
累积确认
- 接收方发送的ACK消息是累积的,表示它已经成功接收了所有序号小于ACK消息中序号的数据包。例如,如果接收方发送ACK5,这意味着它已经成功接收了序号为0到4的所有数据包。
接收窗口大小为1
- 接收方的窗口大小为1,这意味着它只能接收按序号顺序到达的数据包。如果接收到乱序的数据包,接收方会直接丢弃该数据包,并继续等待期望的下一个数据包。
题目中译中
- 发送窗口大小为4:这意味着发送方可以连续发送4个报文,而无需等待确认。
- 序号范围为1024:这表示序号从0到1023,总共1024个序号。
- 接收方期望的下一个报文序号为k:这意味着接收方已经正确接收了序号小于k的所有报文。
- 传输介质不会对报文进行重新排序:这意味着报文在传输过程中不会改变顺序。
解题思路
- a部分:发送方窗口中的序号集合取决于发送方已经发送但尚未收到确认的报文序号。由于窗口大小为4,窗口中的序号应该是连续的4个序号,且这些序号应该在接收方期望的序号k之后。
- b部分:ACK字段的值表示接收方期望接收的下一个报文的序号。由于接收方已经正确接收了序号小于k的所有报文,因此ACK字段的值应该是k。然而,由于可能存在报文丢失或延迟,ACK字段的值可能还包括k之前的序号,因为接收方可能还没有收到某些报文的确认。
最终答案
-
a. 在时间t时,发送方窗口中可能的序号集合是 ({k, k+1, k+2, k+3})。这是因为发送方窗口中的序号应该是连续的4个序号,并且从接收方期望的序号k开始。
-
b. 在时间t时,所有可能正在向发送方传播的报文中的ACK字段的所有可能值是 ({k, k-1, k-2, k-3})。这是因为ACK字段的值表示接收方期望接收的下一个报文的序号,而接收方可能还没有收到某些报文的确认,因此ACK字段的值可能包括k以及k之前的序号。
对比 GBN / SR / TCP 三种重传机制
题目翻译
In this problem, we will compare Go-Back-N, Selective Repeat, and TCP (no delayed ACK). Assume that the timeout values for all three protocols are sufficiently long such that 5 consecutive data segments and their corresponding ACKs can be received (if not lost in the channel) by the receiving host (Host B) and the sending host (Host A) respectively. Suppose Host A sends 5 data segments to Host B, and the 2nd segment (sent from A) is lost. In the end, all 5 data segments have been correctly received by Host B. Suppose that the initial window size for TCP is 5 segments and that the TCP receiver keeps out of order packets in its memory.
在这道题中,我们将比较Go-Back-N、Selective Repeat和TCP(不考虑延迟ACK)。假设所有三种协议的超时时间都足够长,使得5个连续的数据段及其对应的ACK可以被接收主机(主机B)和发送主机(主机A)分别收到(如果它们没有在信道中丢失)。假设主机A向主机B发送了5个数据段,而第2个段(从A发送)丢失了。最终,所有5个数据段都被主机B正确接收。假设TCP的初始窗口大小为5个段,并且TCP接收方会在其内存中保留乱序到达的段。
a. 主机A总共发送了多少个段,主机B总共发送了多少个ACK?它们的序列号是什么?请回答所有三种协议的情况。
a. How many segments has Host A sent in total and how many ACKs has Host B sent in total? What are their sequence numbers? Answer this question for all three protocols.
b. 如果所有三种协议的超时值都远大于5个往返时间(RTT),那么哪种协议在最短的时间间隔内成功地传送了所有五个数据段?
b. If the timeout values for all three protocol are much longer than 5 RTT, then which protocol successfully delivers all five data segments in shortest time interval?
三种方案对比
| 特性/协议 | Go-Back-N (GBN) | Selective Repeat (SR) | TCP (无延迟ACK) |
|---|---|---|---|
| 发送窗口大小 | 可配置,但窗口内所有数据包需按序确认 | 可配置,支持乱序确认 | 动态调整(基于拥塞控制) |
| 接收窗口大小 | 1(只接收按序号顺序的数据包) | 与发送窗口相同(支持乱序缓存) | 与发送窗口类似(支持乱序缓存) |
| 确认机制 | 累积确认(Cumulative ACK) | 选择性确认(Selective ACK) | 选择性确认(Selective ACK) |
| 重传机制 | 从丢失的数据包开始重传所有后续数据包 | 只重传丢失的数据包 | 只重传丢失的数据包(基于冗余ACK或超时) |
| 乱序处理 | 不支持(丢弃乱序数据包) | 支持(缓存乱序数据包) | 支持(缓存乱序数据包) |
| 优点 | 实现简单,可靠性高 | 效率高,支持乱序传输 | 效率高,支持乱序传输,广泛应用于实际网络 |
| 缺点 | 效率低(大量重传),不支持乱序传输 | 实现复杂,需要更多内存 | 实现复杂,需要更多内存,拥塞控制复杂 |
| 适用场景 | 低丢包率、低延迟网络 | 高丢包率、高延迟网络 | 广泛应用于各种网络环境 |
| 示例 | 发送0-4,丢失1,重传1-4 | 发送0-4,丢失1,仅重传1 | 发送0-4,丢失1,仅重传1 |
| ACK示例 | 发送ACK1,ACK5,ACK2,ACK3,ACK4 | 发送ACK0,ACK2,ACK3,ACK4,ACK5 | 发送ACK0,ACK2,ACK3,ACK4,ACK5 |
| 特性 | Selective Repeat (SR) | TCP |
|---|---|---|
| 确认机制 | 选择性确认(Selective ACK) 接收方对每个正确接收的数据包单独发送ACK |
灵活的确认机制: - 默认使用累积确认(Cumulative ACK) - 可选使用选择性确认(SACK) |
| 重传机制 | 只重传丢失的数据包 | 多种重传机制: - 基于超时的重传 - 基于冗余ACK的快速重传 - 使用SACK时,只重传丢失的数据包 |
| 窗口管理 | 发送窗口和接收窗口大小相同,通常固定 | 动态窗口管理,窗口大小根据网络条件动态调整 结合拥塞控制机制 |
| 乱序处理 | 接收方缓存乱序到达的数据包,直到缺失的数据包补全 | 接收方缓存乱序到达的数据包 使用SACK时,更高效地处理乱序数据 |
| 应用场景 | 高丢包率、高延迟的网络环境 理论研究和特定协议设计 |
广泛应用于各种网络环境 局域网、广域网、互联网 |
| 实现复杂度 | 实现相对复杂,需要维护乱序数据包的缓存和复杂的确认机制 | 实现更为复杂,结合多种机制(如SACK、冗余ACK、拥塞控制等) |
| 优点 | 效率高,只重传丢失的数据包 减少不必要的重传 |
灵活性高,适应不同网络条件 强大的拥塞控制机制 |
| 缺点 | 实现复杂,需要更多内存 | 实现复杂,需要更多内存 拥塞控制机制复杂 |
详细解答
好的,我们先将题目翻译成中文,然后再分析这道题的核心考点。
题目翻译
在这道题中,我们将比较Go-Back-N、Selective Repeat和TCP(不考虑延迟ACK)。假设所有三种协议的超时时间都足够长,使得5个连续的数据段及其对应的ACK可以被接收主机(主机B)和发送主机(主机A)分别收到(如果它们没有在信道中丢失)。假设主机A向主机B发送了5个数据段,而第2个段(从A发送)丢失了。最终,所有5个数据段都被主机B正确接收。假设TCP的初始窗口大小为5个段,并且TCP接收方会在其内存中保留乱序到达的段。
a. 主机A总共发送了多少个段,主机B总共发送了多少个ACK?它们的序列号是什么?请回答所有三种协议的情况。
b. 如果所有三种协议的超时值都远大于5个往返时间(RTT),那么哪种协议在最短的时间间隔内成功地传送了所有五个数据段?
详细解答
数据段和ACK的数量及序列号
Go-Back-N (GBN)
- 发送的数据段:主机A最初发送5个数据段(序列号为0到4)。由于第2个段丢失,主机A将重新发送从第2个段开始的所有后续段(序列号为1到4)。因此,主机A总共发送的数据段数为5(初始发送)+ 4(重传)= 9个段。
- 发送的ACK:主机B接收到第1个段后发送ACK1,然后在接收到第5个段后发送ACK5(因为第2个段丢失,第3和第4个段也被丢弃)。在主机A重传后,主机B将接收到第2、3、4个段,并分别发送ACK2、ACK3、ACK4。因此,主机B总共发送的ACK数为5(ACK1、ACK2、ACK3、ACK4、ACK5)。
Selective Repeat (SR)
- 发送的数据段:主机A最初发送5个数据段(序列号为0到4)。由于第2个段丢失,主机A将只重传第2个段(序列号为1)。因此,主机A总共发送的数据段数为5(初始发送)+ 1(重传)= 6个段。
- 发送的ACK:主机B接收到第1、3、4、5个段,并分别为每个段发送ACK。因此,主机B总共发送的ACK数为5(ACK1、ACK3、ACK4、ACK5,以及在收到第2个段后发送的ACK2)。
TCP(无延迟ACK)
- 发送的数据段:主机A最初发送5个数据段(序列号为0到4)。由于第2个段丢失,主机A将只重传第2个段(序列号为1)。因此,主机A总共发送的数据段数为5(初始发送)+ 1(重传)= 6个段。
- 发送的ACK:主机B接收到第1、3、4、5个段,并分别为每个段发送ACK。当主机A重传第2个段后,主机B将发送ACK2。因此,主机B总共发送的ACK数为5(ACK1、ACK3、ACK4、ACK5,以及在收到第2个段后发送的ACK2)。
协议的效率比较
- Go-Back-N (GBN):由于GBN协议在检测到丢失的数据段时会重传从该段开始的所有后续段,因此它的重传数量最多。在本题中,GBN协议总共发送了9个数据段,传输时间最长。
- Selective Repeat (SR) 和 TCP(无延迟ACK):这两种协议只重传丢失的数据段,因此它们的重传数量较少。在本题中,SR和TCP协议总共发送了6个数据段,传输时间相同且最短。
题目和翻译

考虑一个使用8位主机地址的数据报网络。假设一个路由器使用最长前缀匹配,并且具有以下转发表:
| 前缀匹配 | 接口 |
|---|---|
| 00 | 0 |
| 010 | 1 |
| 011 | 2 |
| 10 | 2 |
| 11 | 3 |
对于每个接口,给出与之关联的目的主机地址范围以及范围内的地址数量。
解题思路
这是一道关于最长前缀匹配(Longest Prefix Matching,LPM) 和子网划分的网络题目。它考察的是如何根据路由器的转发表,确定每个接口所对应的地址范围以及范围内的地址数量。这类题目在计算机网络课程中非常常见,尤其是在讨论路由算法和子网划分时。
题目总结
题目给出了一个使用8位主机地址的数据报网络,以及一个路由器的转发表。转发表中列出了不同的前缀匹配规则和对应的接口。要求计算每个接口所对应的地址范围和范围内的地址数量。
解题步骤
理解前缀匹配规则
- 最长前缀匹配(LPM):路由器会根据数据包的目的地址,选择最长匹配的前缀规则来决定转发到哪个接口。
- 前缀长度越长,匹配的地址范围越小;前缀长度越短,匹配的地址范围越大。
确定每个接口的地址范围
- 根据转发表中的前缀,确定每个接口的二进制地址范围。
- 前缀长度决定了地址范围的宽度。例如:
- 前缀长度为2(如
00):匹配的地址范围是00000000到00111111(二进制),即0到63(十进制)。 - 前缀长度为3(如
010):匹配的地址范围是01000000到01011111(二进制),即64到95(十进制)。
- 前缀长度为2(如
计算地址数量
- 地址数量可以通过公式计算:
2^(8 - 前缀长度)。 - 例如:
- 前缀长度为2(如
00):2^(8 - 2) = 2^6 = 64个地址。 - 前缀长度为3(如
010):2^(8 - 3) = 2^5 = 32个地址。
- 前缀长度为2(如
处理重叠范围
- 如果某些前缀的范围有重叠,需要根据最长前缀匹配规则确定优先级。
- 例如,
010和011的范围都属于01的范围,但010和011会优先匹配更长的前缀。
总结每个接口的范围和数量
- 将每个接口的地址范围和数量整理出来,确保覆盖所有可能的地址。
题目解答
| 前缀匹配 | 接口 |
|---|---|
| 00 | 0 |
| 010 | 1 |
| 011 | 2 |
| 10 | 2 |
| 11 | 3 |
-
接口 0:
- 前缀
00,长度为2。 - 地址范围:
00000000到00111111(二进制),即0到63(十进制)。 - 地址数量:
2^(8 - 2) = 64个地址。
- 前缀
-
接口 1:
- 前缀
010,长度为3。 - 地址范围:
01000000到01011111(二进制),即64到95(十进制)。 - 地址数量:
2^(8 - 3) = 32个地址。
- 前缀
-
接口 2:
- 前缀
011和10,长度分别为3和2。 - 地址范围:
01100000到01111111(二进制),即96到127(十进制)。10000000到10111111(二进制),即128到191(十进制)。
- 地址数量:
2^(8 - 3) + 2^(8 - 2) = 32 + 64 = 96个地址。
- 前缀
-
接口 3:
- 前缀
11,长度为2。 - 地址范围:
11000000到11111111(二进制),即192到255(十进制)。 - 地址数量:
2^(8 - 2) = 64个地址。
- 前缀
局域网通过路由器互联
原题与翻译
Consider three LANs interconnected by two routers, as shown in the figure below.
a. Assign IP addresses to all of the interfaces. For Subnet 1 use addresses of the form 192.168.1.xxx; for Subnet 2 uses addresses of the form 192.168.2.xxx; and for Subnet 3 use addresses of the form 192.168.3.xxx.
b. Assign MAC addresses to all of the adapters.
c. Consider sending an IP datagram from Host E to Host B. Suppose all of the ARP tables are up to date. Enumerate the steps by which the datagram reaches its destination, indicating the MAC and IP address used in each step.
d. Repeat (c), now assuming that the ARP table in the sending host is empty (and the other tables are up to date).
题目描述了一个网络拓扑结构,包含三个局域网(LANs),通过两个路由器(Router 1 和 Router 2)互联。题目要求完成以下任务:
- a. 分配 IP 地址:为所有接口分配 IP 地址。
- b. 分配 MAC 地址:为所有适配器分配 MAC 地址。
- c. 数据报传输过程:假设所有 ARP 表都是最新的,描述从 Host E 发送到 Host B 的 IP 数据报的传输过程,包括每一步中使用的 MAC 和 IP 地址。
- d. 数据报传输过程(ARP 表为空):假设发送主机的 ARP 表为空,重复上述过程。
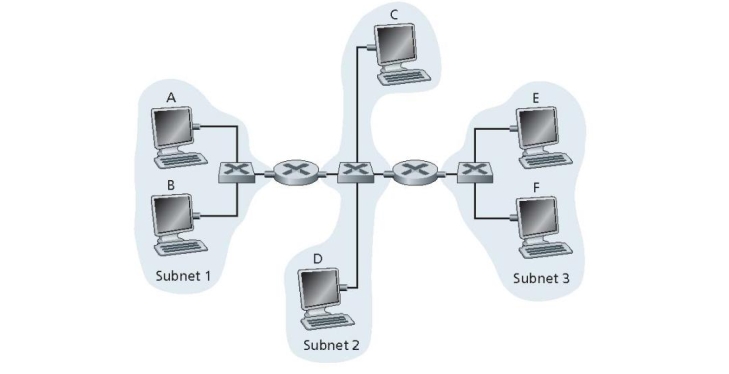
通用方法:IP地址与MAC地址分配及数据报传输分析
IP地址分配
- 步骤:
- 确定子网:根据题目描述,识别出不同的子网(如Subnet 1、Subnet 2等)。
- 选择IP地址范围:根据题目要求,为每个子网分配一个特定的IP地址范围(如
192.168.1.xxx、192.168.2.xxx等)。 - 分配具体IP地址:
- 为主机(Hosts)分配IP地址,通常从子网的第一个可用地址开始(如
192.168.1.1、192.168.1.2等)。 - 为路由器接口分配IP地址,确保每个接口的IP地址与所连接的子网在同一网段内(如Router 1连接到Subnet 1的接口分配
192.168.1.3)。 - 避免IP地址冲突,确保每个设备在子网中具有唯一的IP地址。
- 为主机(Hosts)分配IP地址,通常从子网的第一个可用地址开始(如
- 示例:
- Subnet 1:
192.168.1.xxx- Host A:
192.168.1.1 - Host E:
192.168.1.2 - Router 1(接口连接Subnet 1):
192.168.1.3
- Host A:
- Subnet 2:
192.168.2.xxx- Host B:
192.168.2.1 - Host C:
192.168.2.2 - Router 1(接口连接Subnet 2):
192.168.2.3 - Router 2(接口连接Subnet 2):
192.168.2.4
- Host B:
MAC地址分配
- 步骤:
- 为每个设备分配MAC地址:为主机和路由器接口分配唯一的MAC地址。
- 选择MAC地址格式:MAC地址通常为48位,以十六进制表示(如
00:11:22:33:44:55)。 - 确保唯一性:确保每个设备的MAC地址在局域网中是唯一的,避免冲突。
- 示例:
- Host A:
00:11:22:33:44:55 - Host B:
00:11:22:33:44:66 - Router 1(接口连接Subnet 1):
00:11:22:33:44:AA - Router 1(接口连接Subnet 2):
00:11:22:33:44:BB
数据报传输过程分析
- 步骤:
- 确定源和目标设备:明确数据报的发送源(如Host E)和目标设备(如Host B)。
- 检查目标IP地址是否在本地子网:
- 如果目标IP地址与源设备在同一子网内,直接通过ARP获取目标设备的MAC地址,然后封装并发送数据报。
- 如果目标IP地址不在本地子网内,通过默认网关(路由器)转发。
- ARP表的作用:
- 如果ARP表中有目标IP地址对应的MAC地址,直接使用该MAC地址。
- 如果ARP表为空或没有目标IP地址的记录,发送ARP请求广播帧,获取目标设备或默认网关的MAC地址。
- 数据报封装与转发:
- 封装:将IP数据报封装在以太网帧中,设置源MAC地址和目标MAC地址。
- 转发:根据目标IP地址和路由表,将数据报转发到下一个跳点(可能是路由器或目标主机)。
- 重复上述过程:在每个跳点上重复检查目标IP地址、ARP表查询、封装和转发,直到数据报到达目标主机。
- 示例(Host E发送数据报到Host B,所有ARP表都是最新的):
- Host E:
- 检查目标IP地址(
192.168.2.1)是否在本地子网(192.168.1.0/24)中,发现不在本地子网。 - 查找ARP表,找到默认网关(Router 1)的MAC地址(
00:11:22:33:44:AA)。 - 将数据报封装在以太网帧中,源MAC地址为
00:11:22:33:44:99,目标MAC地址为00:11:22:33:44:AA,IP目的地址为192.168.2.1。 - 发送帧到Router 1。
- 检查目标IP地址(
- Router 1:
- 接收到帧后,检查IP数据报的目的地址(
192.168.2.1)。 - 根据路由表,发现目标地址在Subnet 2中,通过接口(
192.168.2.3)转发。 - 查找ARP表,找到Host B的MAC地址(
00:11:22:33:44:66)。 - 将数据报封装在新的以太网帧中,源MAC地址为
00:11:22:33:44:BB,目标MAC地址为00:11:22:33:44:66,IP目的地址仍为192.168.2.1。 - 发送帧到Host B。
- 接收到帧后,检查IP数据报的目的地址(
- Host B:
- 接收到帧后,检查目标MAC地址是否匹配(
00:11:22:33:44:66)。 - 检查IP数据报的目的地址是否匹配(
192.168.2.1)。 - 数据报到达目的地。
- 接收到帧后,检查目标MAC地址是否匹配(
ARP表为空的情况
- 步骤:
- 发送ARP请求:如果源设备的ARP表中没有目标IP地址的记录,发送ARP请求广播帧,询问目标设备或默认网关的MAC地址。
- 等待ARP响应:目标设备或默认网关收到ARP请求后,发送ARP响应帧,告知其MAC地址。
- 更新ARP表:源设备收到ARP响应后,更新ARP表,记录目标IP地址和对应的MAC地址。
- 重新执行数据报传输过程:使用更新后的ARP表中的MAC地址,重新封装并发送数据报。
- 示例(Host E发送数据报到Host B,ARP表为空):
- Host E:
- 发现目标IP地址(
192.168.2.1)不在本地子网,需要通过默认网关(Router 1)发送。 - 发送ARP请求广播帧,询问
192.168.1.3的MAC地址。 - ARP请求帧的源MAC地址为
00:11:22:33:44:99,目标MAC地址为广播地址FF:FF:FF:FF:FF:FF。
- 发现目标IP地址(
- Router 1:
- 收到ARP请求,发现目标IP地址是自己的接口地址(
192.168.1.3)。 - 发送ARP响应帧,告知Host E自己的MAC地址(
00:11:22:33:44:AA)。
- 收到ARP请求,发现目标IP地址是自己的接口地址(
- Host E:
- 收到ARP响应,更新ARP表,记录Router 1的IP地址(
192.168.1.3)和MAC地址(00:11:22:33:44:AA)。 - 重新封装数据报,源MAC地址为
00:11:22:33:44:99,目标MAC地址为`00:11:22:
- 收到ARP响应,更新ARP表,记录Router 1的IP地址(
题目解答
好的,让我们详细解答你的 Problem 2。题目要求完成以下任务:
- a. 分配 IP 地址
- b. 分配 MAC 地址
- c. 数据报传输过程(所有 ARP 表都是最新的)
- d. 数据报传输过程(发送主机的 ARP 表为空)
以下是基于题目要求的详细解答:
Problem 2: 三个局域网通过两个路由器互联
a. 分配 IP 地址
根据题目要求,为每个接口分配 IP 地址:
- Subnet 1:使用
192.168.1.xxx- Host A:
192.168.1.1 - Host E:
192.168.1.2 - Router 1 接口(连接到 Subnet 1):
192.168.1.3
- Host A:
- Subnet 2:使用
192.168.2.xxx- Host B:
192.168.2.1 - Host C:
192.168.2.2 - Router 1 接口(连接到 Subnet 2):
192.168.2.3 - Router 2 接口(连接到 Subnet 2):
192.168.2.4
- Host B:
- Subnet 3:使用
192.168.3.xxx- Host D:
192.168.3.1 - Router 2 接口(连接到 Subnet 3):
192.168.3.2
- Host D:
b. 分配 MAC 地址
为每个适配器分配 MAC 地址(假设的 MAC 地址,实际中由设备制造商分配):
- Host A:
00:11:22:33:44:55 - Host B:
00:11:22:33:44:66 - Host C:
00:11:22:33:44:77 - Host D:
00:11:22:33:44:88 - Host E:
00:11:22:33:44:99 - Router 1 接口(Subnet 1):
00:11:22:33:44:AA - Router 1 接口(Subnet 2):
00:11:22:33:44:BB - Router 2 接口(Subnet 2):
00:11:22:33:44:CC - Router 2 接口(Subnet 3):
00:11:22:33:44:DD
c. 数据报从 Host E 发送到 Host B(所有 ARP 表都是最新的)
假设所有 ARP 表都是最新的,数据报从 Host E 发送到 Host B 的过程如下:
-
Host E:
- 检查目标 IP 地址(
192.168.2.1)是否在本地子网(192.168.1.0/24)中。发现不在本地子网,因此需要通过默认网关(Router 1 的192.168.1.3)发送。 - 查找 ARP 表,找到 Router 1 的 MAC 地址(
00:11:22:33:44:AA)。 - 将数据报封装在以太网帧中,源 MAC 地址为
00:11:22:33:44:99,目标 MAC 地址为00:11:22:33:44:AA,IP 数据报的目的地址为192.168.2.1。 - 发送帧到 Router 1。
- 检查目标 IP 地址(
-
Router 1:
- 接收到帧后,检查 IP 数据报的目的地址(
192.168.2.1)。 - 根据路由表,发现目标地址在 Subnet 2 中,因此通过接口(
192.168.2.3)转发。 - 查找 ARP 表,找到 Host B 的 MAC 地址(
00:11:22:33:44:66)。 - 将数据报封装在新的以太网帧中,源 MAC 地址为
00:11:22:33:44:BB,目标 MAC 地址为00:11:22:33:44:66,IP 数据报的目的地址仍为192.168.2.1。 - 发送帧到 Host B。
- 接收到帧后,检查 IP 数据报的目的地址(
-
Host B:
- 接收到帧后,检查目标 MAC 地址是否匹配(
00:11:22:33:44:66)。 - 检查 IP 数据报的目的地址是否匹配(
192.168.2.1)。 - 数据报到达目的地。
- 接收到帧后,检查目标 MAC 地址是否匹配(
d. 数据报从 Host E 发送到 Host B(发送主机的 ARP 表为空)
假设发送主机的 ARP 表为空,数据报从 Host E 发送到 Host B 的过程如下:
-
Host E:
- 检查目标 IP 地址(
192.168.2.1)是否在本地子网(192.168.1.0/24)中。发现不在本地子网,因此需要通过默认网关(Router 1 的192.168.1.3)发送。 - 发现 ARP 表为空,因此发送 ARP 请求广播帧,询问
192.168.1.3的 MAC 地址。 - ARP 请求帧的源 MAC 地址为
00:11:22:33:44:99,目标 MAC 地址为广播地址FF:FF:FF:FF:FF:FF。 - 发送 ARP 请求帧到本地子网。
- 检查目标 IP 地址(
-
Router 1:
- 接收到 ARP 请求广播帧,发现目标 IP 地址是自己的接口地址(
192.168.1.3)。 - 发送 ARP 响应帧,告诉 Host E 自己的 MAC 地址(
00:11:22:33:44:AA)。 - ARP 响应帧的源 MAC 地址为
00:11:22:33:44:AA,目标 MAC 地址为00:11:22:33:44:99。
- 接收到 ARP 请求广播帧,发现目标 IP 地址是自己的接口地址(
-
Host E:
- 接收到 ARP 响应帧,更新 ARP 表,记录 Router 1 的 IP 地址(
192.168.1.3)和 MAC 地址(00:11:22:33:44:AA)。 - 将数据报封装在以太网帧中,源 MAC 地址为
00:11:22:33:44:99,目标 MAC 地址为00:11:22:33:44:AA,IP 数据报的目的地址为192.168.2.1。 - 发送帧到 Router 1。
- 接收到 ARP 响应帧,更新 ARP 表,记录 Router 1 的 IP 地址(
-
Router 1:
- 接收到帧后,检查 IP 数据报的目的地址(
192.168.2.1)。 - 根据路由表,发现目标地址在 Subnet 2 中,因此通过接口(
192.168.2.3)转发。 - 查找 ARP 表,找到 Host B 的 MAC 地址(
00:11:22:33:44:66)。 - 将数据报封装在新的以太网帧中,源 MAC 地址为
00:11:22:33:44:BB,目标 MAC 地址为00:11:22:33:44:66,IP 数据报的目的地址仍为 `192.1
- 接收到帧后,检查 IP 数据报的目的地址(
移动互联网相关的
Suppose the correspondent in the figure below were mobile. Sketch the additional network-layer infrastructure that would be needed to route the datagram from the original mobile user to the (now mobile) correspondent. Show the structure of the datagram(s) (include the destination addresses of datagrams) between the original mobile user and the (now mobile) correspondent. Assume indirect routing. You may assign arbitrary addresses where necessary.
假设图中的通信对象(correspondent)是移动的。请绘制出需要的额外网络层基础设施,以便将数据报从原始移动用户路由到(现在也是移动的)通信对象。展示原始移动用户与(现在移动的)通信对象之间数据报的结构(包括数据报的目的地址)。假设采用间接路由。如有必要,可以自行分配地址。
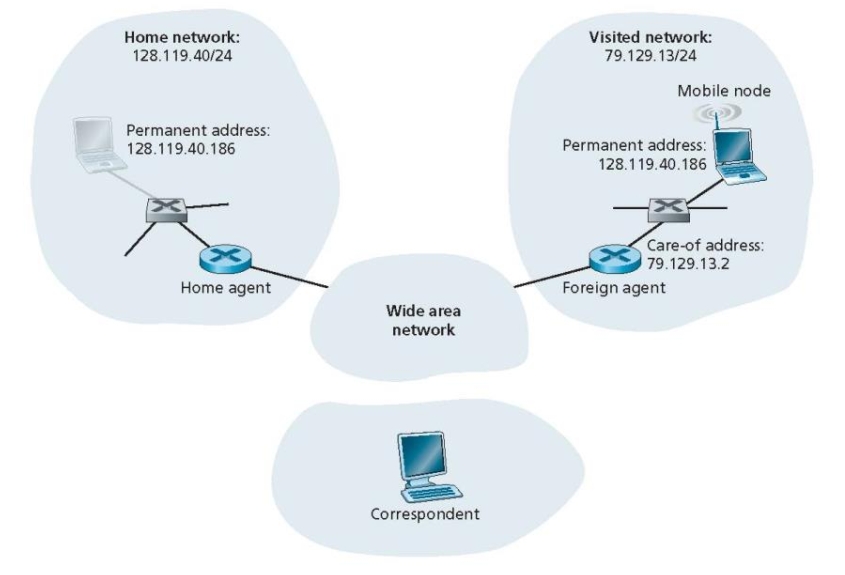
详细解答
场景描述
假设有一个移动通信场景,其中:
- 原始移动用户(MN1):位于家乡网络(Home Network),具有家乡地址(Home Address)。
- 通信对象(MN2):最初位于某个固定网络,现在也变成了移动用户,位于另一个外地网络(Foreign Network)。
- 目标:MN1需要向MN2发送数据报,而MN2现在是移动的,因此需要支持这种移动性。
需要的额外网络层基础设施
为了支持移动性,需要以下网络层基础设施:
- 家乡代理(Home Agent, HA):
- 位于MN1的家乡网络中,负责管理MN1的家乡地址,并转发数据报到MN1的当前位置。
- 地址:
192.168.1.1
- 外地代理(Foreign Agent, FA):
- 位于MN2当前所在的外地网络中,为MN2提供接入服务。
- 地址:
192.168.2.1
- 隧道(Tunneling):
- 用于在家乡代理和外地代理之间转发数据报。
- 注册机制(Registration):
- MN2需要向其家乡代理注册其当前的外地地址(Care-of Address),以便家乡代理能够正确转发数据报。
地址分配
为了简化问题,我们分配以下地址:
- MN1(原始移动用户):
- 家乡地址(Home Address):
192.168.1.10 - 家乡代理(HA):
192.168.1.1
- 家乡地址(Home Address):
- MN2(现在移动的通信对象):
- 家乡地址(Home Address):
192.168.2.10 - 当前外地代理(FA):
192.168.2.1 - 当前外地地址(Care-of Address):
192.168.2.100
- 家乡地址(Home Address):
数据报传输过程
假设采用间接路由,数据报从MN1发送到MN2的过程如下:
-
MN1发送数据报:
- MN1构造一个数据报,目标地址是MN2的家乡地址
192.168.2.10。 - 数据报被发送到MN1的家乡代理(HA)。
数据报结构:
1 2源地址:192.168.1.10 目的地址:192.168.2.10 - MN1构造一个数据报,目标地址是MN2的家乡地址
-
家乡代理(HA)处理数据报:
- HA收到数据报后,检查其注册表,发现MN2当前的外地地址是
192.168.2.100。 - HA将数据报封装在隧道中,发送到MN2的外地代理(FA)。
封装后的数据报结构:
1 2 3 4 5 6外层 IP 头部: 源地址:192.168.1.1(HA) 目的地址:192.168.2.1(FA) 内层 IP 头部(原始数据报): 源地址:192.168.1.10(MN1) 目的地址:192.168.2.10(MN2的家乡地址) - HA收到数据报后,检查其注册表,发现MN2当前的外地地址是
-
外地代理(FA)处理数据报:
- FA收到封装的数据报后,解封装并转发给MN2。
- FA将数据报的目的地址改为MN2的外地地址
192.168.2.100。
解封装后的数据报结构:
1 2源地址:192.168.1.10(MN1) 目的地址:192.168.2.100(MN2的外地地址) -
MN2接收数据报:
- MN2收到数据报后,识别出其外地地址
192.168.2.100,并处理数据报。 - MN2可以回复数据报,回复过程类似,但方向相反。
- MN2收到数据报后,识别出其外地地址
数据报结构示意图
以下是数据报在不同阶段的结构示意图:
MN1发送的数据报:
|
|
HA封装后的数据报:
|
|
FA解封装后的数据报:
|
|
MN2接收的数据报:
|
|
总结
通过上述步骤,我们可以看到,为了支持移动性,需要额外的网络层基础设施(如家乡代理、外地代理和隧道)来确保数据报能够正确地从原始移动用户路由到移动的通信对象。整个过程涉及封装、解封装和地址转换,以确保数据报能够到达正确的目的地。
视频流的播放和缓冲区管理
原文和翻译
a.
英文原文:
Client begins playout as soon as the first block arrives at$t_1$ and video blocks are to be played out over the fixed amount of time,$\Delta$. So it follows that the second video block should arrive before time$t_1 + \Delta$ to be played at the right time, the third block at$t_1 + 2\Delta$, and so on. We can see from the figure that only blocks numbered 1, 4, 5, and 6 arrive at the receiver before their playout times.
中文翻译:
客户端在第一个视频块到达时(时间$t_1$)立即开始播放,视频块将在固定的时间间隔$\Delta$ 内播放。因此,第二个视频块需要在$t_1 + \Delta$ 之前到达,以便按时播放;第三个视频块需要在$t_1 + 2\Delta$ 之前到达,依此类推。从图中可以看出,只有编号为 1、4、5 和 6 的视频块在它们的播放时间之前到达了接收端。
b.
英文原文:
Client begins playout at time$t_1 + \Delta$ and video blocks are to be played out over the fixed amount of time,$\Delta$. So it follows that the second video block should arrive before time$t_1 + 2\Delta$ to be played at the right time, the third block at$t_1 + 3\Delta$, and so on. We can see from the figure that video blocks numbered from 1 to 6, except 7, arrive at the receiver before their playout times.
中文翻译:
客户端在第一个视频块到达后延迟$\Delta$ 时间(即在$t_1 + \Delta$)开始播放,视频块将在固定的时间间隔$\Delta$ 内播放。因此,第二个视频块需要在$t_1 + 2\Delta$ 之前到达,以便按时播放;第三个视频块需要在$t_1 + 3\Delta$ 之前到达,依此类推。从图中可以看出,除了编号为 7 的视频块之外,编号为 1 到 6 的视频块都在它们的播放时间之前到达了接收端。
c.
英文原文:
Maximum two video blocks are ever stored in the client buffer. Video blocks numbered 3 and 4 arrive before$t_1 + 3\Delta$ and after$t_1 + 2\Delta$, hence these two blocks are stored in the client buffer. Video block numbered 5 arrives before time$t_1 + 4\Delta$ and after$t_1 + 3\Delta$, which is stored in the client buffer along with already stored video block numbered 4.
中文翻译:
客户端缓冲区最多存储两个视频块。编号为 3 和 4 的视频块在$t_1 + 3\Delta$ 之前、( t_1 + 2\Delta$ 之后到达,因此这两个块被存储在客户端缓冲区中。编号为 5 的视频块在$t_1 + 4\Delta$ 之前、( t_1 + 3\Delta$ 之后到达,因此它与已经存储的编号为 4 的视频块一起存储在客户端缓冲区中。
d.
英文原文:
The smallest playout at the client should be$t_1 + 3\Delta$ to ensure that every block has arrived in time.
中文翻译:
客户端的最小播放时间应该是$t_1 + 3\Delta$,以确保所有视频块都能及时到达。
详细解答
a. 客户端在第一个视频块到达时立即开始播放
- 条件:
- 客户端在第一个视频块到达时(时间$t_1$)立即开始播放。
- 每个视频块的播放时间是固定的,记为$\Delta$。
- 因此,第二个视频块需要在$t_1 + \Delta$ 之前到达,第三个视频块需要在$t_1 + 2\Delta$ 之前到达,依此类推。
- 分析:
- 从图中可以看到,只有编号为 1、4、5 和 6 的视频块在它们的播放时间之前到达了接收端。
- 其他视频块(如编号为 2 和 3 的块)到达的时间晚于它们的播放时间,因此无法及时播放。
b. 客户端在第一个视频块到达后延迟$\Delta$ 时间开始播放
- 条件:
- 客户端在第一个视频块到达后延迟$\Delta$ 时间(即在$t_1 + \Delta$)开始播放。
- 每个视频块的播放时间仍然是固定的$\Delta$。
- 因此,第二个视频块需要在$t_1 + 2\Delta$ 之前到达,第三个视频块需要在$t_1 + 3\Delta$ 之前到达,依此类推。
- 分析:
- 从图中可以看到,除了编号为 7 的视频块之外,编号为 1 到 6 的视频块都在它们的播放时间之前到达了接收端。
- 编号为 7 的视频块到达的时间晚于$t_1 + 6\Delta$,因此无法及时播放。
c. 客户端缓冲区的最大存储情况
- 条件:
- 客户端缓冲区最多可以存储两个视频块。
- 视频块 3 和 4 在$t_1 + 2\Delta$ 之后、( t_1 + 3\Delta$ 之前到达,因此这两个块被存储在客户端缓冲区中。
- 视频块 5 在$t_1 + 3\Delta$ 之后、( t_1 + 4\Delta$ 之前到达,因此它与已经存储的视频块 4 一起存储在客户端缓冲区中。
- 分析:
- 在$t_1 + 2\Delta$ 时,缓冲区存储了视频块 3 和 4。
- 在$t_1 + 3\Delta$ 时,视频块 5 到达,缓冲区存储了视频块 4 和 5。
- 缓冲区最多存储两个视频块,因此当新的视频块到达时,旧的视频块会被播放并从缓冲区中移除。
d. 客户端的最小播放时间
- 条件:
- 客户端需要确保每个视频块都能及时到达并播放。
- 从前面的分析中,我们知道视频块 3 和 4 在$t_1 + 2\Delta$ 之后到达,因此客户端需要等待到$t_1 + 3\Delta$ 才能开始播放,以确保所有视频块都能及时到达。
- 分析:
- 最小的播放时间应该是$t_1 + 3\Delta$,这样可以确保所有视频块都能在播放之前到达客户端。
通过上述分析,我们可以得出以下结论:
- a. 只有编号为 1、4、5 和 6 的视频块能够在播放时间之前到达。
- b. 除了编号为 7 的视频块之外,编号为 1 到 6 的视频块都能在播放时间之前到达。
- c. 客户端缓冲区最多存储两个视频块,具体存储情况取决于视频块的到达时间。
- d. 客户端的最小播放时间应该是$t_1 + 3\Delta$,以确保所有视频块都能及时到达并播放。
令牌桶算法
题目描述
这是第一题
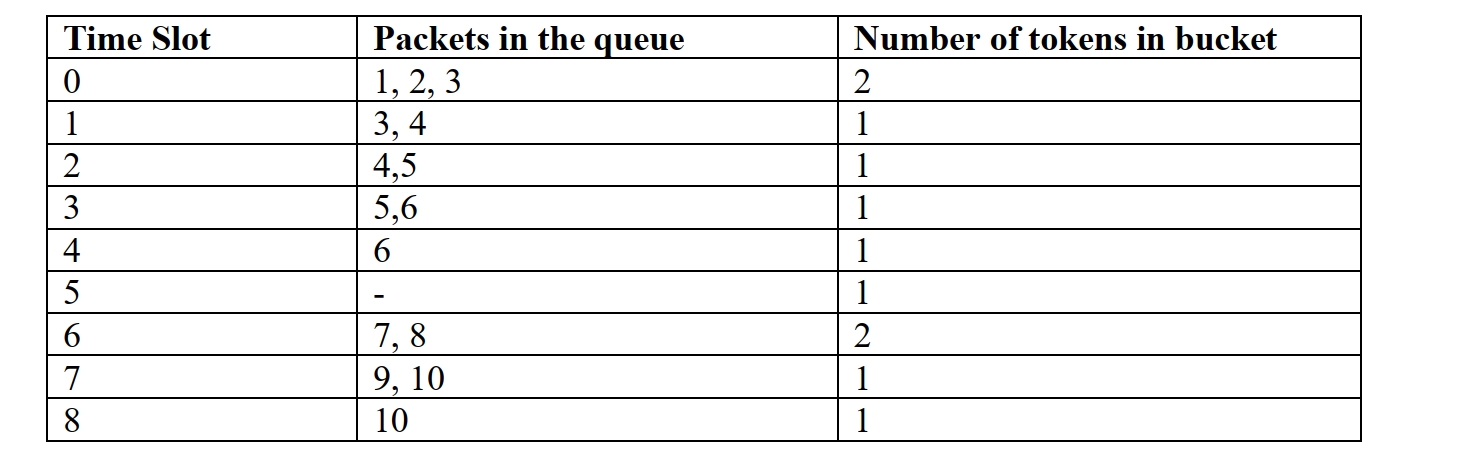
这是第二题

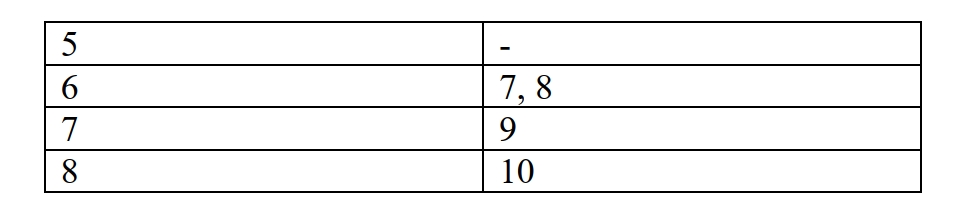
令牌桶算法(Token Bucket Algorithm)
定义
令牌桶算法是一种用于**流量整形(Traffic Shaping)和流量控制(Traffic Policing)**的算法。它通过限制数据包的发送速率,确保网络流量符合预定的速率限制,从而避免网络拥塞。
工作原理
令牌桶算法的核心思想是使用一个“令牌桶”来控制数据包的发送。具体步骤如下:
-
令牌生成:
- 令牌以固定的速率(如每秒1个令牌)生成,并放入令牌桶中。
- 令牌桶有一个最大容量,当桶满时,多余的令牌会被丢弃。
-
数据包发送:
- 每个数据包需要消耗一个令牌才能发送。
- 当有数据包到达时,系统会检查令牌桶中是否有足够的令牌。
- 如果有令牌,系统会取出一个令牌并发送数据包。
- 如果没有令牌,数据包会被排队等待,直到有足够的令牌。
-
排队和缓冲:
- 如果数据包到达速率超过令牌生成速率,多余的包会被放入一个队列中等待发送。
- 队列中的数据包按顺序发送,每次发送时消耗一个令牌。
参数
令牌桶算法通常由以下参数定义:
- 令牌生成速率(r):每秒生成的令牌数量。
- 令牌桶容量(b):令牌桶的最大容量,即桶中最多可以存储的令牌数量。
- 突发量(burst size):允许的最大突发数据量,通常等于令牌桶容量。
作用
- 流量整形(Traffic Shaping):通过控制数据包的发送速率,使流量更加平滑,避免突发流量对网络造成冲击。
- 流量控制(Traffic Policing):限制流量的最大速率,确保网络资源的公平使用。
示例
假设:
- 令牌生成速率$r = 1$ 个令牌/秒。
- 令牌桶容量$b = 3$ 个令牌。
- 数据包到达速率为 2 个包/秒。
时间槽分析:
- 时间槽 0:
- 令牌桶中有 3 个令牌(初始满桶)。
- 到达 2 个数据包,发送 2 个数据包,消耗 2 个令牌。
- 令牌桶剩余 1 个令牌。
- 时间槽 1:
- 令牌桶新增 1 个令牌,现在有 2 个令牌。
- 到达 2 个数据包,发送 2 个数据包,消耗 2 个令牌。
- 令牌桶剩余 0 个令牌。
- 时间槽 2:
- 令牌桶新增 1 个令牌,现在有 1 个令牌。
- 到达 2 个数据包,只能发送 1 个数据包,消耗 1 个令牌。
- 令牌桶剩余 0 个令牌,1 个数据包排队等待。
- 时间槽 3:
- 令牌桶新增 1 个令牌,现在有 1 个令牌。
- 发送排队中的 1 个数据包,消耗 1 个令牌。
- 令牌桶剩余 0 个令牌,队列为空。
通过这种方式,令牌桶算法可以有效地控制流量,确保网络资源的合理利用。
不知道是啥的画图题
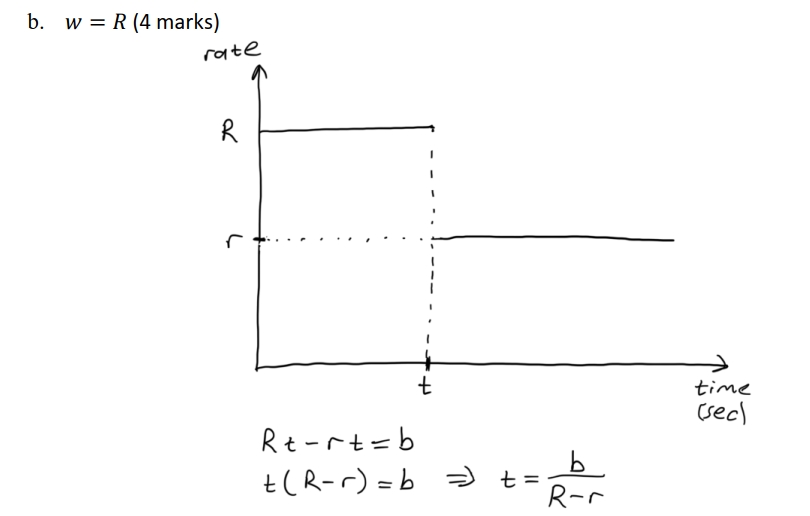

公钥与私钥相关的攻击
老师给的答案

t鲍勃最初不知道自己是在和特鲁迪(Trudy)还是爱丽丝(Alice)交谈。鲍勃和爱丽丝共享一个秘密密钥$K_{AB}$,而特鲁迪不知道这个密钥。特鲁迪希望鲍勃将她(特鲁迪)认证为爱丽丝。特鲁迪打算让鲍勃先进行身份认证,然后等待鲍勃开始:
- 鲍勃对特鲁迪:“我是鲍勃” 评论:鲍勃开始对自己进行认证。鲍勃对另一方的身份认证随后暂停了几个步骤。
- 特鲁迪对鲍勃:“我是爱丽丝” 评论:特鲁迪开始将自己认证为爱丽丝。
- 鲍勃对特鲁迪:“R” 评论:鲍勃对第 2 步作出回应,通过回复一个随机数(nonce)。 特鲁迪还不知道$K_{AB}(R)$,因此她还无法回复。
- 特鲁迪对鲍勃:“R” 评论:特鲁迪现在回应第 1 步,继续鲍勃的认证过程,她选择鲍勃在第 3 步让她加密的完全相同的值作为鲍勃要加密的随机数。
- 鲍勃对特鲁迪:“( K_{AB}(R)$” 鲍勃通过加密他在第 4 步收到的随机数,完成了对自己身份的认证。特鲁迪现在有了$K_{AB}(R)$。(注意:她并不需要拥有$K_{AB}$)
- 特鲁迪对鲍勃:“( K_{AB}(R)$” 特鲁迪完成了她的认证,用$K_{AB}(R)$ 回应鲍勃在第 3 步发送的随机数$R$。由于特鲁迪返回了鲍勃在第 3 步发送的正确加密的随机数,鲍勃认为特鲁迪是爱丽丝。
重新解释一下这个过程
这是一个关于网络安全和身份认证的问题,具体涉及密钥共享、身份伪装和认证协议。题目描述了一个经典的网络攻击场景,展示了攻击者如何通过伪装和利用协议漏洞欺骗合法用户。以下是题目的背景和具体内容的详细解释:
-
角色:
- Bob:一个合法用户,希望与另一个用户进行安全通信。
- Alice:Bob的通信伙伴,Bob期望与她进行通信。
- Trudy:攻击者,她试图伪装成Alice,欺骗Bob。
-
密钥共享:
- Bob和Alice共享一个秘密密钥$K_{AB}$,这个密钥只有他们两人知道,Trudy不知道这个密钥。
题目描述了一个身份认证过程,其中Bob试图验证他正在与Alice通信,但Trudy试图伪装成Alice欺骗Bob。整个过程如下:
-
Bob开始认证自己:
- Bob向Trudy发送消息:“我是Bob”,表明他开始进行身份认证。
- 这一步主要是Bob向对方表明身份,但认证过程尚未完成。
-
Trudy伪装成Alice:
- Trudy收到Bob的消息后,回应:“我是Alice”。
- 这一步中,Trudy试图欺骗Bob,让他认为自己是Alice。
-
Bob发送随机数(nonce):
- Bob向Trudy发送一个随机数$R$,这是身份认证过程中的一个关键步骤。
- Bob希望通过加密这个随机数来验证对方是否拥有共享密钥$K_{AB}$。
-
Trudy利用Bob的随机数:
- Trudy收到Bob发送的随机数$R$ 后,她并不知道如何用密钥$K_{AB}$ 加密这个随机数,因为她没有这个密钥。
- 但是,Trudy聪明地将Bob发送的随机数$R$ 原样返回给Bob,试图继续欺骗他。
-
Bob完成自己的认证:
- Bob收到Trudy返回的随机数$R$ 后,用自己的密钥$K_{AB}$ 对$R$ 进行加密,并将加密结果$K_{AB}(R)$ 发送给Trudy。
- 这一步中,Bob完成了对自己身份的认证,但他并不知道Trudy并不是Alice。
-
Trudy完成伪装:
- Trudy收到Bob发送的加密随机数$K_{AB}(R)$ 后,将这个加密结果原样返回给Bob。
- Bob收到Trudy返回的加密随机数$K_{AB}(R)$ 后,认为Trudy是Alice,因为Bob认为只有Alice才能正确返回加密的随机数。
-
攻击原理:
- Trudy利用了Bob的身份认证协议中的漏洞。Bob在认证过程中没有验证对方的身份,而是直接发送了一个随机数$R$ 并等待对方返回加密结果。
- Trudy通过原样返回Bob发送的随机数$R$,并最终返回Bob加密后的结果$K_{AB}(R)$,成功欺骗了Bob。
-
问题的核心:
- 这个问题展示了身份认证协议中可能存在的漏洞,特别是当协议没有正确验证对方身份时,攻击者可以通过伪装和利用协议的漏洞欺骗合法用户。
-
解决方案:
- 为了解决这个问题,Bob和Alice可以采用更安全的身份认证协议,例如使用数字签名、双向认证或更复杂的挑战-响应机制,确保对方的身份是真实的。
身份认证协议
身份认证协议(Authentication Protocol)是一种用于验证通信双方身份的协议。它的核心目标是确保通信的对方是声称的那个人,从而防止伪装、重放攻击等安全威胁。身份认证协议是网络安全的基础,广泛应用于各种网络通信场景,如登录系统、金融交易、物联网设备通信等。
身份认证协议的重要性
在网络安全中,身份认证是确保通信安全的第一步。如果身份认证失败,攻击者可能会伪装成合法用户,从而获取敏感信息、篡改数据或进行其他恶意行为。身份认证协议的重要性体现在以下几个方面:
- 防止伪装攻击:确保通信的对方是声称的那个人,而不是伪装者。
- 防止重放攻击:防止攻击者截获合法通信并重新发送,以欺骗接收者。
- 确保通信的保密性和完整性:通过身份认证,可以为后续的加密和消息认证提供基础。
身份认证协议的常见类型
身份认证协议可以根据不同的实现机制和应用场景分为以下几类:
基于共享密钥的身份认证协议
在这种协议中,通信双方共享一个秘密密钥 K,用于验证对方的身份。常见的实现方式包括:
- 挑战-响应机制:
- 发送方:Alice向Bob发送一个随机数 R(挑战)。
- 接收方:Bob使用共享密钥 K 对随机数 R 进行加密,生成响应 K(R) 并返回给Alice。
- 验证:Alice收到响应后,使用相同的密钥 K 对随机数 R 进行加密,验证Bob返回的响应是否一致。
- 消息认证码(MAC):
- 发送方:Alice将消息 m 和共享密钥 K 结合,生成消息认证码 H(K;m)。
- 接收方:Bob收到消息和认证码后,使用相同的密钥 K 和算法重新计算认证码,验证消息的完整性和来源。
基于非对称加密的身份认证协议
在这种协议中,通信双方使用非对称加密技术(如RSA、ECC等)进行身份认证。常见的实现方式包括:
-
数字签名:
- 发送方:Alice使用自己的私钥对消息 m 进行签名,生成签名 SignAlice(m)。
- 接收方:Bob收到消息和签名后,使用Alice的公钥验证签名,从而确认消息确实来自Alice。
-
证书机制:
- 证书颁发机构(CA):CA为用户颁发数字证书,证书中包含用户的公钥和身份信息。
- 通信过程:Alice向Bob发送自己的数字证书,Bob通过验证证书的有效性来确认Alice的身份。
消息认证码(MAC)的安全性和如何防止消息重放或重排序攻击
AI猜测的问题
假设爱丽丝(Alice)和鲍勃(Bob)通过共享密钥 K 来生成消息认证码(MAC),以确保消息的完整性和来源。他们使用以下机制来验证消息:
- 每条消息 mi 都附带一个消息认证码 H(K;mi),其中 H 是一个安全的哈希函数。
请回答以下问题:
a) 鲍勃(Bob)是否能够验证爱丽丝(Alice)发送的每条消息的来源?他是否能够保证消息的顺序?为什么?
b) 如果爱丽丝(Alice)希望防止消息被重排序攻击,她可以采取什么措施?请提出一种改进方案。
老师的答案

a) 鲍勃可以验证爱丽丝至少发送了每条消息一次,因为除了鲍勃之外,爱丽丝是唯一知道密钥 K 的人,因此也是唯一能够生成 H(K;mi) 的人。消息的顺序无法保证,因为攻击者可以截获消息及其消息认证码(MAC),然后在发送给鲍勃之前替换它们的顺序。
b) 爱丽丝可以在每条消息认证码中添加时间戳,即 H(K;ti;mi)。
根据提供的答案内容,我可以推测出问题可能与消息认证码(MAC)的安全性和如何防止消息重放或重排序攻击有关。以下是可能的问题描述:
尝试还原题目
假设爱丽丝(Alice)和鲍勃(Bob)通过共享密钥$K$ 来生成消息认证码(MAC),以确保消息的完整性和来源。他们使用以下机制来验证消息:
- 每条消息$m_i$ 都附带一个消息认证码$H(K; m_i)$,其中$H$ 是一个安全的哈希函数。
请回答以下问题:
a) 鲍勃(Bob)是否能够验证爱丽丝(Alice)发送的每条消息的来源?他是否能够保证消息的顺序?为什么?
b) 如果爱丽丝(Alice)希望防止消息被重排序攻击,她可以采取什么措施?请提出一种改进方案。
a) 验证消息来源和顺序
- 验证来源:鲍勃可以验证每条消息是否由爱丽丝发送。因为只有爱丽丝和鲍勃知道共享密钥$K$,因此只有他们能够生成正确的消息认证码$H(K; m_i)$。如果消息认证码验证通过,鲍勃可以确信消息是由爱丽丝发送的。
- 保证顺序:鲍勃无法保证消息的顺序。攻击者可以截获消息及其消息认证码,然后重新排列它们的顺序再发送给鲍勃。由于消息认证码中没有包含顺序信息,鲍勃无法区分消息的原始顺序。
b) 防止重排序攻击
- 改进方案:爱丽丝可以在每条消息认证码中添加时间戳$t_i$。这样,消息认证码变为$H(K; t_i; m_i)$。时间戳$t_i$ 是消息发送的时间标记,鲍勃收到消息后可以通过时间戳来检查消息的顺序。如果消息被重排序,时间戳的顺序也会被打乱,鲍勃可以检测到这种异常。
消息认证码 MAC
消息认证码(Message Authentication Code,简称MAC)是一种用于验证消息完整性和来源安全性的技术。它通过结合消息内容和一个共享密钥生成一个固定长度的认证码,从而确保消息在传输过程中未被篡改,并且消息确实来自声称的发送者。以下是关于消息认证码安全性的详细解释,包括它的原理、优势、潜在漏洞以及如何增强其安全性。
消息认证码的基本原理
消息认证码的生成过程通常涉及以下步骤:
- 共享密钥:通信双方(例如Alice和Bob)共享一个秘密密钥$K$。这个密钥必须保密,只有通信双方知道。
- 消息和密钥结合:发送方(Alice)将要发送的消息$m$ 和共享密钥$K$ 结合,通过一个特定的算法(通常是哈希函数或加密算法)生成一个固定长度的认证码$\text{MAC}$。
- 发送消息和认证码:Alice将消息$m$ 和生成的认证码$\text{MAC}$ 一起发送给Bob。
- 验证认证码:Bob收到消息和认证码后,使用相同的密钥$K$ 和算法重新计算认证码。如果Bob计算的认证码与Alice发送的认证码一致,那么Bob可以确信消息未被篡改,并且确实来自Alice。
消息认证码的安全性优势
- 验证消息完整性:通过对比计算得到的认证码和接收到的认证码,接收者可以检测出消息在传输过程中是否被篡改。如果消息被篡改,即使只改动一个字节,重新计算的认证码也会与原始认证码不匹配。
- 验证消息来源:由于只有通信双方知道共享密钥$K$,因此只有Alice能够生成与密钥匹配的认证码。这使得Bob可以确信消息确实来自Alice,而不是伪造的。
- 防止重放攻击:如果每次通信都使用不同的消息或认证码,攻击者无法简单地重放旧的消息来欺骗接收者。
消息认证码的潜在漏洞
- 密钥泄露风险:如果共享密钥$K$ 被泄露,攻击者可以伪造消息和认证码,从而绕过MAC的安全性。因此,密钥的保密性至关重要。
- 无法保证消息顺序:如第二题中提到的,如果消息认证码中没有包含顺序信息,攻击者可以截获消息并重新排列它们的顺序,接收者无法检测到这种顺序变化。
- 无法防止消息重放:如果攻击者截获了消息和认证码,他们可以将这些消息重新发送给接收者。虽然接收者可以验证消息的完整性和来源,但无法判断消息是否是重复发送的。
如何增强消息认证码的安全性
- 使用安全的哈希函数:选择一个抗碰撞和抗预像攻击的哈希函数(如SHA-256或SHA-3)来生成认证码,可以提高MAC的安全性。
- 添加时间戳:在消息认证码中加入时间戳$t$,例如$\text{MAC} = H(K; t; m)$。这样,即使消息被重放,时间戳也会暴露攻击行为。同时,时间戳可以帮助接收者检测消息的顺序。
- 使用唯一标识符:为每条消息分配一个唯一的序列号或随机数(nonce),并将其包含在认证码中。这样可以确保每条消息的唯一性,防止重放攻击。
- 定期更换密钥:定期更换共享密钥可以降低密钥被泄露的风险,从而增强系统的安全性。
- 结合数字签名:虽然MAC依赖共享密钥,但数字签名使用非对称加密技术,可以提供更强的来源验证和不可否认性。结合使用MAC和数字签名可以提供更全面的安全性。
消息重排序攻击
好的!接下来我们详细探讨消息重排序攻击以及如何通过添加时间戳或其他机制来防止这种攻击。
消息重排序攻击的背景
在网络安全中,消息重排序攻击是一种常见的威胁。攻击者通过截获合法通信中的消息,然后重新排列消息的发送顺序,试图欺骗接收者。这种攻击可能导致接收者误解消息的真实意图,从而引发安全问题。
假设Alice和Bob正在通过网络通信,Alice发送了以下两条消息:
- 消息1:
转账100元给Bob,附带MAC:H(K; m1) - 消息2:
转账200元给Bob,附带MAC:H(K; m2)
如果攻击者截获了这两条消息,并将它们的顺序调换,Bob收到的消息顺序就会变成:
- 消息2:
转账200元给Bob - 消息1:
转账100元给Bob
Bob可能会误以为Alice先要求转账200元,然后再要求转账100元,从而导致误解甚至错误操作。
消息认证码(MAC)的局限性
虽然消息认证码(MAC)可以验证消息的完整性和来源,但它本身无法保证消息的顺序。原因如下:
- MAC的生成机制:MAC是通过将消息内容和共享密钥结合生成的,但它不包含消息的发送顺序信息。
- 攻击者的篡改能力:攻击者可以截获消息及其MAC,然后重新排列它们的顺序,接收者无法通过MAC检测到这种顺序变化。
如何防止消息重排序攻击
为了防止消息重排序攻击,需要在消息认证码中加入额外的信息,以确保消息的顺序。以下是两种常见的解决方案:
-
方法1:添加时间戳
- 时间戳是一种简单而有效的方法,用于防止消息重排序攻击。具体步骤如下:
- 发送方添加时间戳:Alice在发送消息时,为每条消息添加一个时间戳$t_i$,表示消息的发送时间。然后生成包含时间戳的MAC:
H(K; t_i; m_i)。 - 接收方验证时间戳:Bob收到消息后,首先验证MAC是否正确。如果MAC验证通过,Bob会检查时间戳$t_i$,确保消息的顺序与时间戳的顺序一致。
- 发送方添加时间戳:Alice在发送消息时,为每条消息添加一个时间戳$t_i$,表示消息的发送时间。然后生成包含时间戳的MAC:
- 举例说明:
- 消息1:
转账100元给Bob,时间戳:2025-04-14 10:00,MAC:H(K; 2025-04-14 10:00; m1) - 消息2:
转账200元给Bob,时间戳:2025-04-14 10:05,MAC:H(K; 2025-04-14 10:05; m2)
- 消息1:
- 如果攻击者调换了这两条消息的顺序,Bob会发现时间戳的顺序与消息的接收顺序不一致,从而检测到攻击行为。
- 时间戳是一种简单而有效的方法,用于防止消息重排序攻击。具体步骤如下:
-
方法2:使用序列号
- 序列号是另一种防止消息重排序攻击的方法。具体步骤如下:
- 发送方添加序列号:Alice为每条消息分配一个唯一的序列号$n_i$,并将其包含在MAC中:
H(K; n_i; m_i)。 - 接收方验证序列号:Bob收到消息后,验证MAC是否正确,并检查序列号$n_i$ 是否按顺序递增。如果序列号的顺序被打乱,Bob可以检测到这种异常。
- 发送方添加序列号:Alice为每条消息分配一个唯一的序列号$n_i$,并将其包含在MAC中:
- 举例说明:
- 消息1:
转账100元给Bob,序列号:1,MAC:H(K; 1; m1) - 消息2:
转账200元给Bob,序列号:2,MAC:H(K; 2; m2)
- 消息1:
- 如果攻击者调换了这两条消息的顺序,Bob会发现序列号的顺序与消息的接收顺序不一致,从而检测到攻击行为。
- 序列号是另一种防止消息重排序攻击的方法。具体步骤如下:
时间戳和序列号的比较
- 时间戳:
- 优点:时间戳可以提供更直观的时间顺序,适用于需要精确时间记录的场景。
- 缺点:如果发送方和接收方的时钟不同步,可能会导致验证失败。
- 序列号:
- 优点:序列号简单且易于实现,不受时钟同步问题的影响。
- 缺点:如果消息丢失或重复,序列号可能会出现跳号或重复的情况,需要额外的机制来处理。